
SQLでフルテーブルスキャンになる原因と回避方法まとめ
筆者も仕事中、バッチ処理の性能劣化を調査していた際に、あるSELECT文が突然極端に遅くなった経験があります。実行計画を確認すると、原因はフルテーブルスキャンでした。インデックスは作成済みで「問題ないはず」と思い込んでいたのですが、実際には条件式の書き方や統計情報の未更新が影響していました。
フルテーブルスキャンは「インデックスがない」だけが原因ではありません。SQLの書き方、データ量の変化、統計情報、暗黙の型変換など、複数の要因が絡みます。
本記事では、フルテーブルスキャンが発生する具体的な原因と、現場で使える回避方法を体系的にまとめます。
フルテーブルスキャンとは何か
フルテーブルスキャンとは、テーブル内の全レコードを順番に読み込んで検索する処理です。インデックスを使用せず、物理的にテーブル全体を走査します。
データ件数が少ない場合は問題になりませんが、数十万件・数百万件規模になると以下の問題が発生します。
| 項目 | 内容 |
|---|---|
| 処理時間 | データ量に比例して増加 |
| CPU負荷 | 高くなりやすい |
| I/O負荷 | ディスクアクセスが増加 |
| 他処理への影響 | ロック競合や待ち時間増加 |
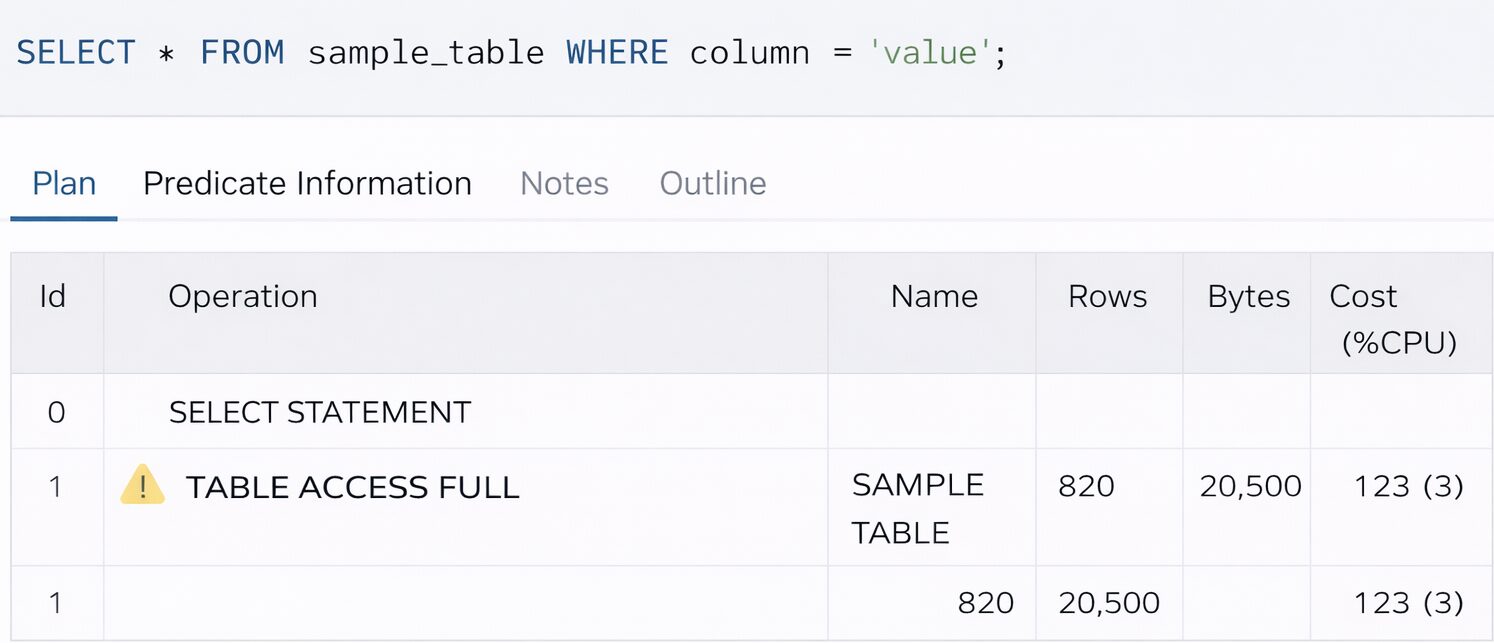
DBMSによっては「TABLE ACCESS FULL」などと実行計画に表示されます。
フルテーブルスキャンになる主な原因
インデックスを作成しているのにフルテーブルスキャンになる場合は、SQLの書き方に原因がある可能性があります。LIKE検索や関数の使用、暗黙的な型変換によってINDEXが無効化される具体例は、以下の記事で詳しく解説しています。

1. インデックスが存在しない
もっとも単純な原因です。WHERE句に指定した列にインデックスがなければ、フルテーブルスキャンになる可能性が高くなります。
例:
|
1 |
SELECT * FROM users WHERE email = 'test@example.com'; |
email列にインデックスがなければ全件検索になります。
回避策:
|
1 |
CREATE INDEX idx_users_email ON users(email); |
2. インデックスはあるが使用されない
インデックスが存在しても、オプティマイザが「使わない」と判断するケースがあります。
主な理由は以下です。
| 原因 | 説明 |
|---|---|
| 取得件数が多い | 全体の大半を取得する場合はフルスキャンの方が高速 |
| 統計情報が古い | データ分布を誤認識 |
| カーディナリティが低い | 値の種類が少ない列 |
例:性別やフラグ列など。
回避策:
・統計情報の更新(ANALYZE TABLE など)
・選択度の高い列にインデックスを作成
3. 関数を使用している
インデックス列に対して関数を使用すると、通常のインデックスが使用されません。
例:
|
1 2 |
SELECT * FROM orders WHERE TO_CHAR(order_date, 'YYYYMM') = '202601'; |
この場合、order_dateのインデックスは使用されません。
回避策:
|
1 2 3 |
SELECT * FROM orders WHERE order_date >= DATE '2026-01-01' AND order_date < DATE '2026-02-01'; |
関数を使わず範囲検索に変更します。
4. 暗黙の型変換
列のデータ型と比較値の型が一致しない場合、暗黙の型変換が発生し、インデックスが使われないことがあります。
例:
user_id が NUMBER型なのに
|
1 |
WHERE user_id = '100'; |
のように文字列で比較すると変換が発生します。
回避策:
型を一致させる。
|
1 |
WHERE user_id = 100; |
5. LIKE検索の前方ワイルドカード
LIKE ‘%abc’ のような検索は、インデックスを使用できません。
例:
|
1 |
WHERE name LIKE '%山田'; |
回避策:
・前方一致にする(LIKE ‘山田%’)
・全文検索インデックスの利用
6. OR条件の多用
OR条件はインデックスが効きにくい場合があります。
例:
|
1 2 |
WHERE status = 'A' OR status = 'B'; |
回避策:
IN句に変更
|
1 |
WHERE status IN ('A','B'); |
またはUNIONに分割する方法もあります。
7. 複合インデックスの順序不一致
複合インデックスは、定義順が重要です。
例:
|
1 2 |
CREATE INDEX idx_orders_user_date ON orders(user_id, order_date); |
この場合、
|
1 |
WHERE order_date = DATE '2026-01-01'; |
だけではインデックスが使われません。
回避策:
・先頭列を条件に含める
・必要に応じて別インデックスを作成
実行計画の確認方法
問題の切り分けには、実行計画の確認が不可欠です。
代表的な確認方法:
| DB | コマンド例 |
|---|---|
| Oracle | EXPLAIN PLAN FOR ~ |
| MySQL | EXPLAIN SELECT ~ |
| PostgreSQL | EXPLAIN ANALYZE |
実行計画で「TABLE ACCESS FULL」や「Seq Scan」と表示されていないか確認します。
フルテーブルスキャンを回避する実践チェックリスト
以下の順番で確認すると効率的です。
- インデックスは存在するか
- 統計情報は最新か
- WHERE句で関数を使っていないか
- 型は一致しているか
- LIKEで前方ワイルドカードを使っていないか
- 複合インデックスの順序は適切か
- 実行計画を確認したか
よくある質問(Q & A)
- フルテーブルスキャンは絶対に悪いのですか?
-
いいえ。取得件数が多い場合やテーブルが小さい場合は、フルテーブルスキャンの方が高速なこともあります。重要なのは「意図せず発生していないか」です。
- インデックスを増やせば必ず速くなりますか?
-
いいえ。インデックスが増えるとINSERTやUPDATEが遅くなります。用途に応じて設計する必要があります。
- 統計情報はどのくらいの頻度で更新すべきですか?
-
データ増減が多いテーブルは定期的な更新が推奨されます。バッチ処理後に更新する運用も一般的です。
まとめ
フルテーブルスキャンは「インデックス不足」だけが原因ではありません。関数使用、型不一致、統計情報未更新、複合インデックスの順序など、SQLの書き方と設計が大きく影響します。
性能問題が発生した場合は、まず実行計画を確認し、感覚ではなく事実で判断することが重要です。適切なインデックス設計とSQLの見直しにより、多くの問題は解決できます。