
本記事では、Google TPU(Tensor Processing Unit)とは何か、GPUとの違い、性能差、そしてどのような用途に向くのかを、初めて触れる人にも分かりやすく解説します。
「結局どっち使えばいいの?」という疑問に答える実務目線の内容です。
目次
-
Google TPUとは?
-
GPUとの構造的な違い
-
TPUとGPUの性能差(実例つき)
-
向いている用途・向いていない用途
-
実務での選び方(どっちを使うべき?)
-
まとめ
1. Google TPUとは?
TPU(Tensor Processing Unit)とは、Google が「機械学習専用」に開発したプロセッサです。
特に TensorFlow・JAX といったフレームワークと相性が良く、
行列演算(Matrix Multiply)を専用ハードウェアで爆速処理できるという特徴があります。
✔ TPUの特徴(要点)
-
AI専用に設計された専用チップ
-
巨大な行列処理ユニット(MXU:Matrix Multiply Unit)を搭載
-
Google Cloud 上で利用(ローカル利用不可)
-
学習も推論も高速化できる
-
電力効率が高い
Google 検索、翻訳、写真(画像認識)など Google サービス内部でも大量に使われています。
2. GPUとの構造的な違い
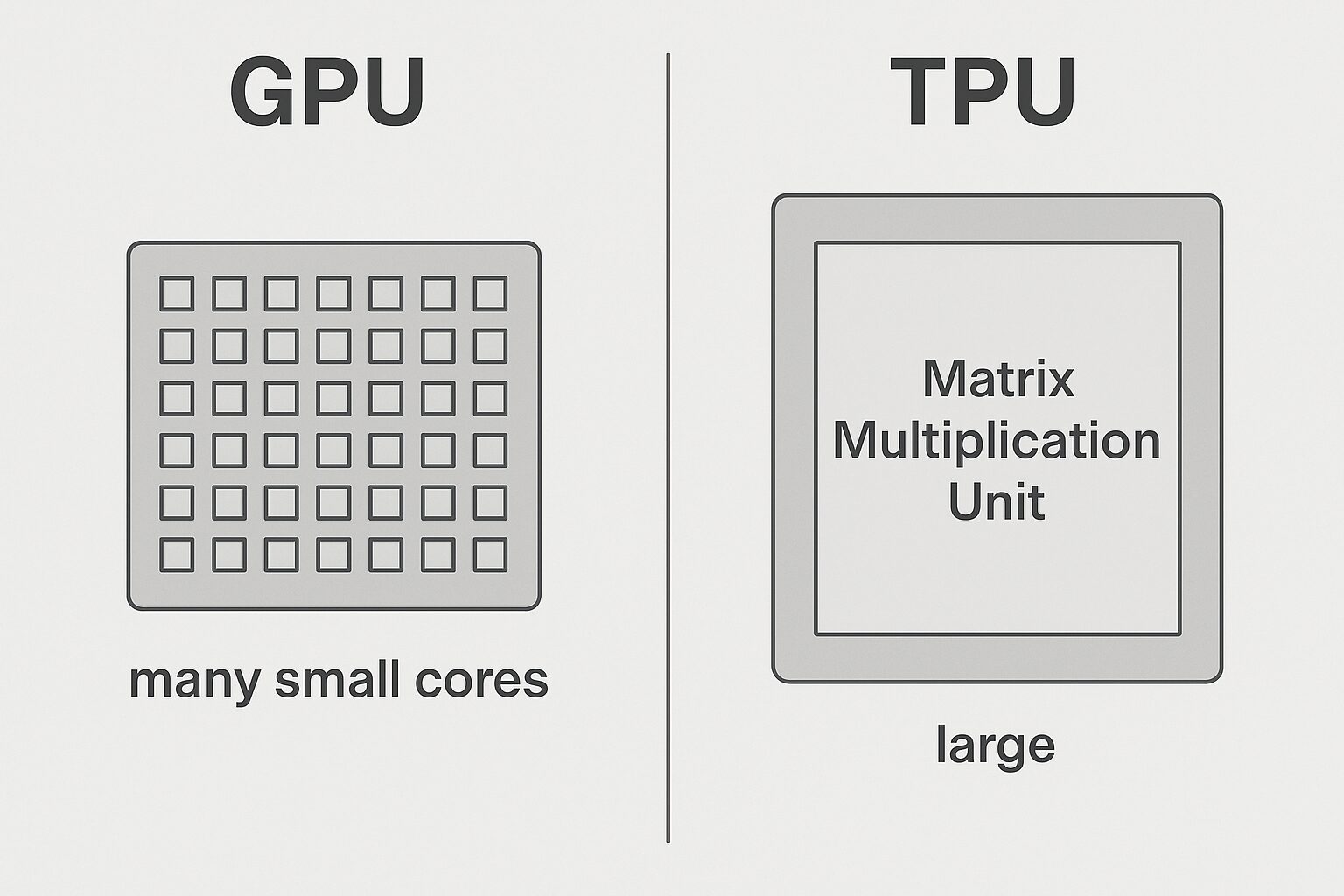
🔵 GPU(汎用型の並列演算プロセッサ)
元はゲーム・グラフィックス用に開発されたハードウェア。
数千〜1万個以上のコアで並列処理を実現し、汎用的な高速演算が得意です。
特徴:
-
グラフィック処理からAIまで幅広く対応
-
PyTorch / TensorFlow / Stable Diffusionなど何でも動く
-
ローカルPCでも利用可能
代表例:NVIDIA RTX / H100 / A100 など
🔴 TPU(AI特化型プロセッサ)
GPUのような汎用性はなく、AIの行列演算に全振りした構造。
特徴:
-
超大型の行列演算ユニットで一括処理
-
TensorFlow・JAXに最適化
-
Google Cloud 専用
GPUと比較すると、
「グラフィックも数値もやる万能選手(GPU)」
「AIだけを極めた専門職(TPU)」
という違いです。
3. TPUとGPUの性能差(実例つき)
Google のベンチマーク例をもとにした、ざっくり比較がこちら👇
■ 学習速度の違い(TensorFlow)
| モデル | GPU (NVIDIA A100) | TPU v4 | 差 |
|---|---|---|---|
| ResNet-50 | 約6.5時間 | 約2.2時間 | 約3倍高速 |
| BERT-Large | 約2.5時間 | 約1.2時間 | 約2倍高速 |
👉 行列計算が支配的なモデルほど、TPUが圧倒的に速い
■ スケール性能
TPU は「8個セット」や「Pod(数百台規模)」の構成が標準化されており、
追加ノードによるスケールが非常に素直で速いという特徴があります。
GPU でもスケールは可能ですが、
-
バラつく同期
-
ノード間通信オーバーヘッド
などが発生するため、大規模学習ではTPUの効率が勝ちます。
■ 電力効率
TPU の強みです。
Google は「同等性能で GPU の約1/2〜1/3 の電力」と公表しています。
4. TPUに向いている用途・向いていない用途
✔ TPUが向いているケース
-
TensorFlow / JAX を使うプロジェクト
-
BERT / GPT / Vision Transformer など大規模モデル
-
数十台〜数百台規模での大規模分散学習
-
Google Cloud を利用した高速学習
✘ TPUが向かないケース
-
PyTorch がメイン(互換はあるが性能最適化はされてない)
-
Stable Diffusion / LoRA などの生成AI用途
-
ローカルで計算したい
-
グラフィックス用途(動画編集・ゲームなど)
5. 実務での選び方(どっちを使うべき?)
🔵 GPUを選ぶべきケース
-
PyTorch や生成AIを使う
-
ローカルPC(Windows / Linux)で処理したい
-
AI以外の用途も扱う(動画、解析など)
-
柔軟性を重視
→ 個人利用・汎用利用ならほぼGPU一択
🔴 TPUを選ぶべきケース
-
Google Cloud 上で TensorFlow を使った大規模学習
-
BERT/GPT クラスの高度なモデルを高速化したい
-
学習コスト(電力・時間)を最適化したい
→ 企業や研究機関での大量学習向け
6. まとめ
| 項目 | GPU | TPU |
|---|---|---|
| 用途 | 汎用 | AI専用 |
| 使える場所 | ローカル+クラウド | Google Cloudのみ |
| 速度 | 速い | AIモデル学習はより速い |
| 電力効率 | 普通 | 非常に優秀 |
| 対応フレームワーク | ほぼ全部 | TensorFlow / JAX中心 |
| 個人向け | ◎ | △ |
| 企業・研究向け | ◎ | ◎(大規模学習時) |
結論:
-
個人・中小規模 → GPU
-
大規模TensorFlowプロジェクト → TPU
あなたが扱っている生成AI・画像・動画系なら、基本GPUの方が適しています。


