
運用保守を担当していた業務システムで、夜間バッチが突然停止し、ログに「ORA-00060」や「Transaction (Process ID …) was deadlocked」と出力されたことがあります。最初はSQLの書き方を疑いましたが、実際の原因はトランザクション設計でした。
結論として、デッドロックの主因は「ロック取得順の不統一」と「長時間トランザクション」です。SQL単体の問題ではなく、設計と運用の問題で発生していることが多いです。
本記事ではOracle DatabaseとMicrosoft SQL Serverの両方を前提に、発生原因と実践的な回避方法を整理します。
デッドロックとは何か
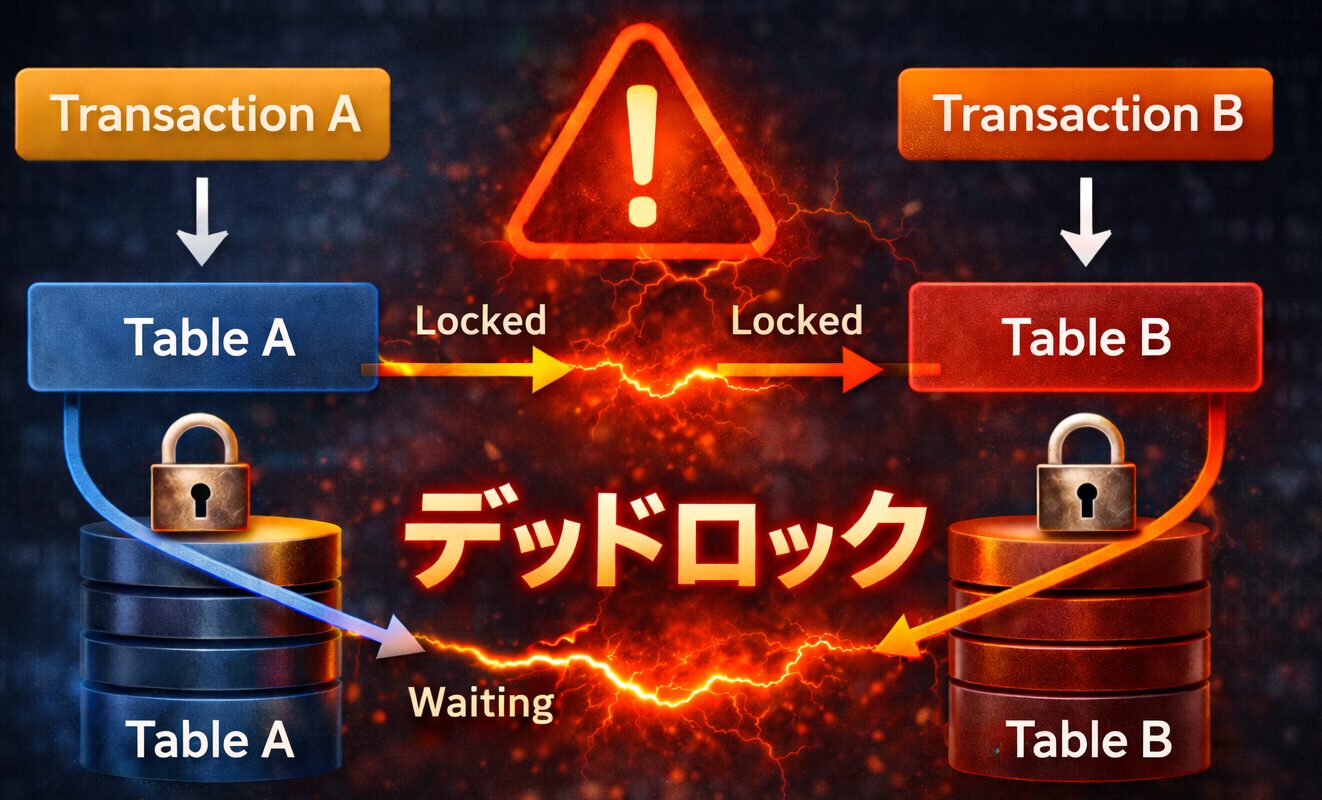
デッドロックとは、複数のトランザクションが互いにロックを保持しながら、相手のロック解放を待ち続ける状態です。
例:
- トランザクションA
テーブルAをロック → テーブルBを更新しようとする - トランザクションB
テーブルBをロック → テーブルAを更新しようとする
この状態になると、AもBも処理が進みません。
Oracleでは一方が自動的にロールバックされ、ORA-00060が発生します。
SQL Serverではデッドロック検出後、優先度の低いトランザクションが終了しエラーが返ります。
Oracle環境で実際に発生する代表的なエラーが「ORA-00060: デッドロックが検出されました」です。
ログの見方やトレースファイルの確認方法、具体的な解決手順を詳しく知りたい場合は、以下の記事も参考にしてください。

OracleとSQL Serverの違い
| 項目 | Oracle Database | Microsoft SQL Server |
|---|---|---|
| エラー例 | ORA-00060: deadlock detected while waiting for resource | Transaction was deadlocked on lock resources |
| ロック方式 | 行レベルロック中心(MVCC) | 行・ページ・テーブルロック |
| デッドロック検出 | 自動検出 | 自動検出 |
| 犠牲トランザクション | 自動ロールバック | 自動選定(優先度で決定可) |
| 設定項目 | INITRANS、SELECT FOR UPDATE | DEADLOCK_PRIORITY、LOCK_TIMEOUT |
Oracleはマルチバージョン同時実行制御(MVCC)を採用しているため、読み取りでは基本的にブロックが発生しません。しかし更新系処理ではロック競合が発生します。
SQL Serverはロックベース制御のため、設計次第でロック範囲が拡大しやすい特徴があります。
デッドロックが発生する主な原因
1. ロック取得順が統一されていない
最も多い原因です。
例:
- 処理A:顧客テーブル → 注文テーブル
- 処理B:注文テーブル → 顧客テーブル
順番を統一するだけで解消できるケースは非常に多いです。
2. トランザクションが長い
BEGINからCOMMITまでの時間が長いと、ロック保持時間が延びます。
原因例:
- 不要な処理をトランザクション内で実行
- 画面入力待ち中もロック保持
- 大量更新を1回で実行
3. インデックス不足
WHERE句にインデックスがないと、フルスキャンが発生し、多数の行がロック対象になります。
SQL Serverではロックエスカレーションが発生し、ページロックやテーブルロックに拡大する場合があります。
4. SELECT FOR UPDATEの多用(Oracle)
OracleでSELECT FOR UPDATEを不用意に使うと、明示的に行ロックがかかります。必要最小限にするべきです。
5. 同一データへの高頻度更新
在庫数や連番管理など、同一行を頻繁に更新する設計はデッドロックの温床になります。
デッドロックの確認方法
Oracle
以下のビューで確認できます。
- V$SESSION
- V$LOCK
- DBA_BLOCKERS
- DBA_WAITERS
トレースファイルにデッドロックグラフが出力されます。
SQL Server
- SQL Server Management Studioのデッドロックグラフ
- sys.dm_tran_locks
- sys.dm_os_waiting_tasks
- 拡張イベント(Extended Events)
回避方法まとめ
1. ロック取得順を統一する
設計ルールとして「テーブルA → テーブルB → テーブルC」の順を固定します。
これだけで大半のデッドロックは防げます。
2. トランザクションを短くする
悪い例:
- BEGIN
- データ取得
- ユーザー入力待ち
- UPDATE
- COMMIT
正しい例:
- 入力完了後にBEGIN
- 必要な更新のみ実行
- すぐCOMMIT
3. 適切なインデックスを作成する
UPDATEやDELETEの検索条件列にインデックスを付与します。
実行計画を確認し、テーブルスキャンを回避します。
4. バッチを分割する
大量更新は件数を分割し、コミットを小分けにします。
5. SQL Serverでの優先度制御
SQL Serverでは以下の設定が可能です。
SET DEADLOCK_PRIORITY LOW
優先度を下げることで、特定処理を犠牲トランザクションにできます。
6. LOCK_TIMEOUT設定(SQL Server)
SET LOCK_TIMEOUT 5000
指定時間待機後にエラーにできます。
よくある質問(Q & A)
- デッドロックとロック待ちの違いは何ですか?
-
ロック待ちは一方向の待機です。デッドロックは双方が互いを待ち合う状態です。
- OracleはMVCCだからデッドロックは起きませんか?
-
発生します。更新系処理では行ロックがかかります。
- インデックスを付ければ必ず防げますか?
-
いいえ。取得順不統一や長時間トランザクションは防げません。
- デッドロックは完全に防げますか?
-
設計段階で対策すれば大幅に減らせますが、ゼロ保証は困難です。
まとめ
デッドロックの主因は以下の3点です。
- ロック取得順が統一されていない
- トランザクションが長い
- インデックス不足によるロック拡大
OracleでもSQL Serverでも、基本原則は同じです。
SQLの書き方よりも「設計」と「トランザクション管理」が重要です。
発生後に慌てるのではなく、設計段階で予防することが最善策です。

")
