
SQLをチューニングする際、「INDEXを作成したのに処理が遅い」「想定通りにINDEXが使われていない」と感じた経験は多いのではないでしょうか。
この問題は、単純にINDEXが不足しているのではなく、SQLの書き方そのものが原因であるケースが非常に多く見られます。
本記事では、INDEXが効かなくなる代表的な原因として、LIKE検索、関数の使用、暗黙的な型変換の3点に焦点を当て、なぜINDEXが使われなくなるのか、どのように書き換えるべきかを具体例とともに解説します。
INDEXが使われる条件とは?仕組みを簡潔に解説
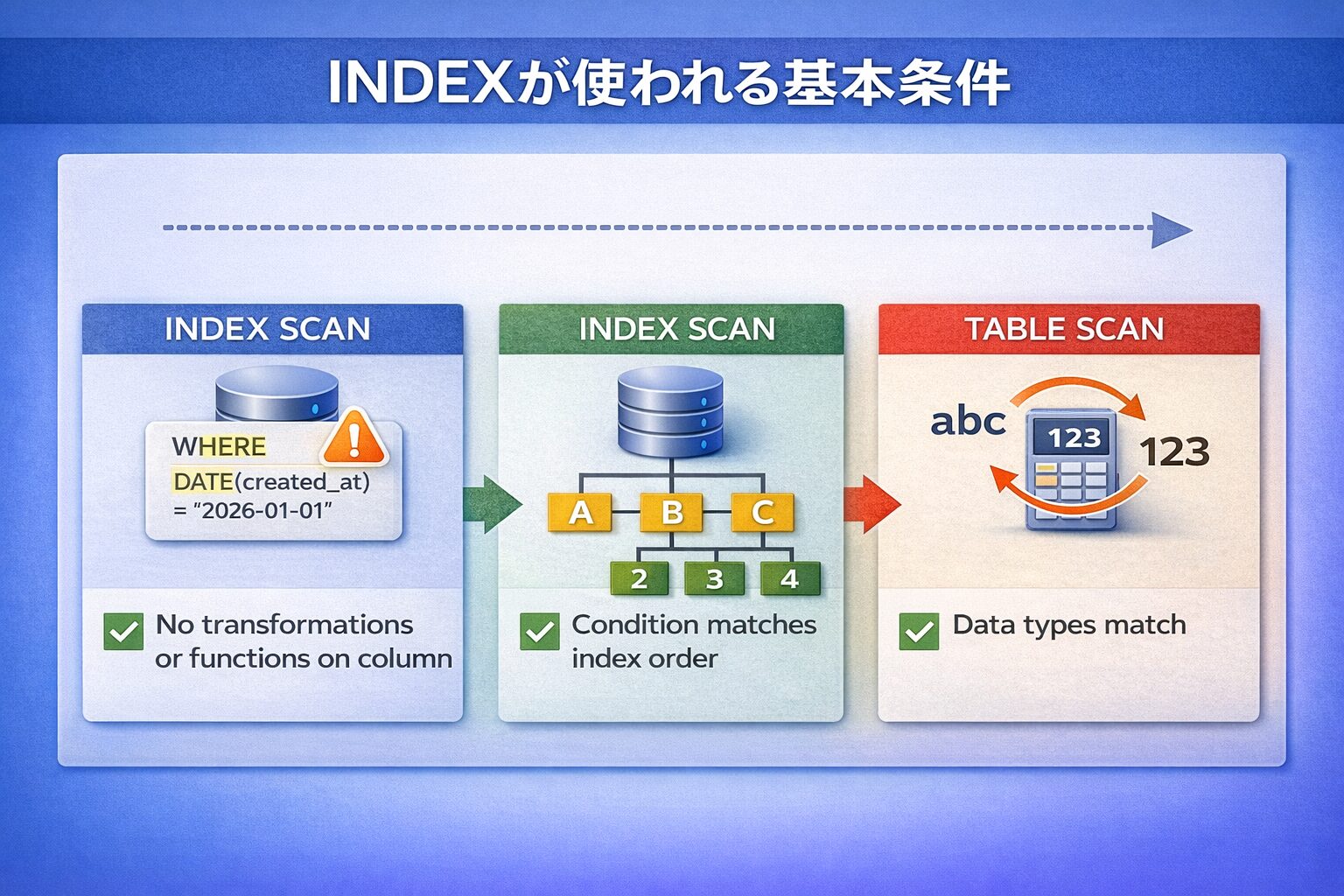
まず前提として、INDEXは「WHERE句で指定した条件をもとに、対象行を素早く絞り込む」ための仕組みです。
データベースは、INDEXを使うことで全件走査(フルスキャン)を回避し、必要な行だけを効率良く取得します。
しかし、以下のような場合にはINDEXの利用が難しくなります。
・列に対して加工や変換が行われている
・検索条件がINDEXの並び順と一致していない
・比較対象のデータ型が一致していない
これらは一見些細な違いに見えますが、実行計画に大きな影響を与えます。
LIKE検索でINDEXが効かない原因と回避方法
LIKE検索は文字列検索で頻繁に使用されますが、書き方によってはINDEXがまったく利用されません。
前方一致・中間一致・後方一致の違い
次のようなSQLを比較してみます。
|
1 |
WHERE name LIKE 'ABC%' |
このような前方一致検索は、INDEXが利用される可能性があります。
理由は、検索条件の先頭が固定されており、INDEXの並び順を活用できるためです。
一方で、以下のような書き方は注意が必要です。
|
1 2 |
WHERE name LIKE '%ABC' WHERE name LIKE '%ABC%' |
これらは後方一致や中間一致となり、INDEXは基本的に使用されません。
先頭がワイルドカード(%)の場合、どの値から検索を開始すべきか判断できないため、全件走査が選択されます。
対策の考え方
・前方一致で検索できる設計に変更する
・検索用に別の列を用意する
・全文検索インデックスなど、用途に合った仕組みを利用する
LIKE検索を多用する設計では、最初からINDEXが使えないケースがあることを前提に検討する必要があります。
WHERE句で関数を使うとINDEXが効かない理由
INDEXが効かない原因として非常に多いのが、列に対して関数を適用しているケースです。
典型的な例
|
1 |
WHERE TO_CHAR(created_at, 'YYYYMMDD') = '20260101' |
このSQLでは、created_at列に関数が適用されています。
その結果、データベースはINDEX上の値をそのまま利用できず、全行に対して関数を評価する必要が生じます。
INDEXを効かせる書き方
次のように条件を変更すると、INDEXが利用される可能性が高まります。
|
1 2 |
WHERE created_at >= DATE '2026-01-01' AND created_at < DATE '2026-01-02' |
列側を加工せず、比較値側を調整することが重要です。
よくある関数使用例
・TO_CHAR
・SUBSTR
・UPPER / LOWER
・TRUNC
これらをWHERE句で使用する場合は、INDEXが効かなくなる可能性を常に意識する必要があります。
暗黙的な型変換でINDEXが使われないケース
暗黙的変換は、SQL上ではエラーにならないため見落とされがちですが、パフォーマンス面では非常に危険です。
数値列と文字列の比較
|
1 |
WHERE user_id = '100' |
user_idが数値型の場合、データベースは内部で暗黙的な型変換を行います。
多くのDBでは、列側が変換対象となるため、結果としてINDEXが使われません。
日付列との文字列比較
|
1 |
WHERE created_at = '2026-01-01' |
このような比較も暗黙的変換が発生します。
見た目は正しくても、実行計画上はフルスキャンになる可能性があります。
明示的に型を合わせる
|
1 |
WHERE user_id = 100 |
|
1 |
WHERE created_at = DATE '2026-01-01' |
比較するデータ型を明示的に合わせることで、INDEXが正しく利用されるようになります。
複合インデックスの順序が原因でINDEXが使われないケース
複合インデックス(複数カラムに対して作成されたインデックス)は、定義したカラムの順序が非常に重要です。順序を誤ると、インデックスが存在していても実行計画では使用されず、フルテーブルスキャンになることがあります。
たとえば、以下のような複合インデックスがあるとします。
|
1 |
CREATE INDEX idx_user ON users (department_id, created_at); |
この場合、インデックスは
- department_id
- created_at
の順で並んでいます。
✔ インデックスが使われる例
|
1 |
WHERE department_id = 10 |
または
|
1 2 |
WHERE department_id = 10 AND created_at >= '2024-01-01' |
このように、先頭カラム(department_id)から条件指定している場合は、インデックスが有効に使われやすくなります。
✖ インデックスが使われない例
|
1 |
WHERE created_at >= '2024-01-01' |
この場合、先頭カラムである department_id を指定していないため、インデックスは十分に活用できません。DBのオプティマイザは効率が悪いと判断し、テーブルスキャンを選択する可能性があります。
なぜ順序が重要なのか?
複合インデックスは「左から順に」検索される仕組みになっています。
これを 最左プレフィックス(Leftmost Prefix) と呼びます。
つまり、
- 先頭カラムを使わない検索
- 途中のカラムだけを使う検索
では、インデックスの効果が発揮されません。
対処方法
- 検索条件のパターンを分析する
- よく使うWHERE条件の順序に合わせてインデックスを設計する
- 必要に応じて別の単一インデックスを追加する
インデックスは「とりあえず複合で作る」のではなく、実際の検索条件に合わせて設計することが重要です。
実行計画で Index Seek になっているかどうかを必ず確認し、意図通りに使われているかをチェックしましょう。
実行計画でINDEXが使われているか確認する方法
INDEXが使われているかどうかは、実行計画を確認しなければ判断できません。
「INDEXがある=使われる」と思い込むのは非常に危険です。
実行計画を見ることで、以下を確認できます。
・INDEX SCAN か TABLE SCAN か
・想定外のフルスキャンが発生していないか
・条件の書き方が最適か
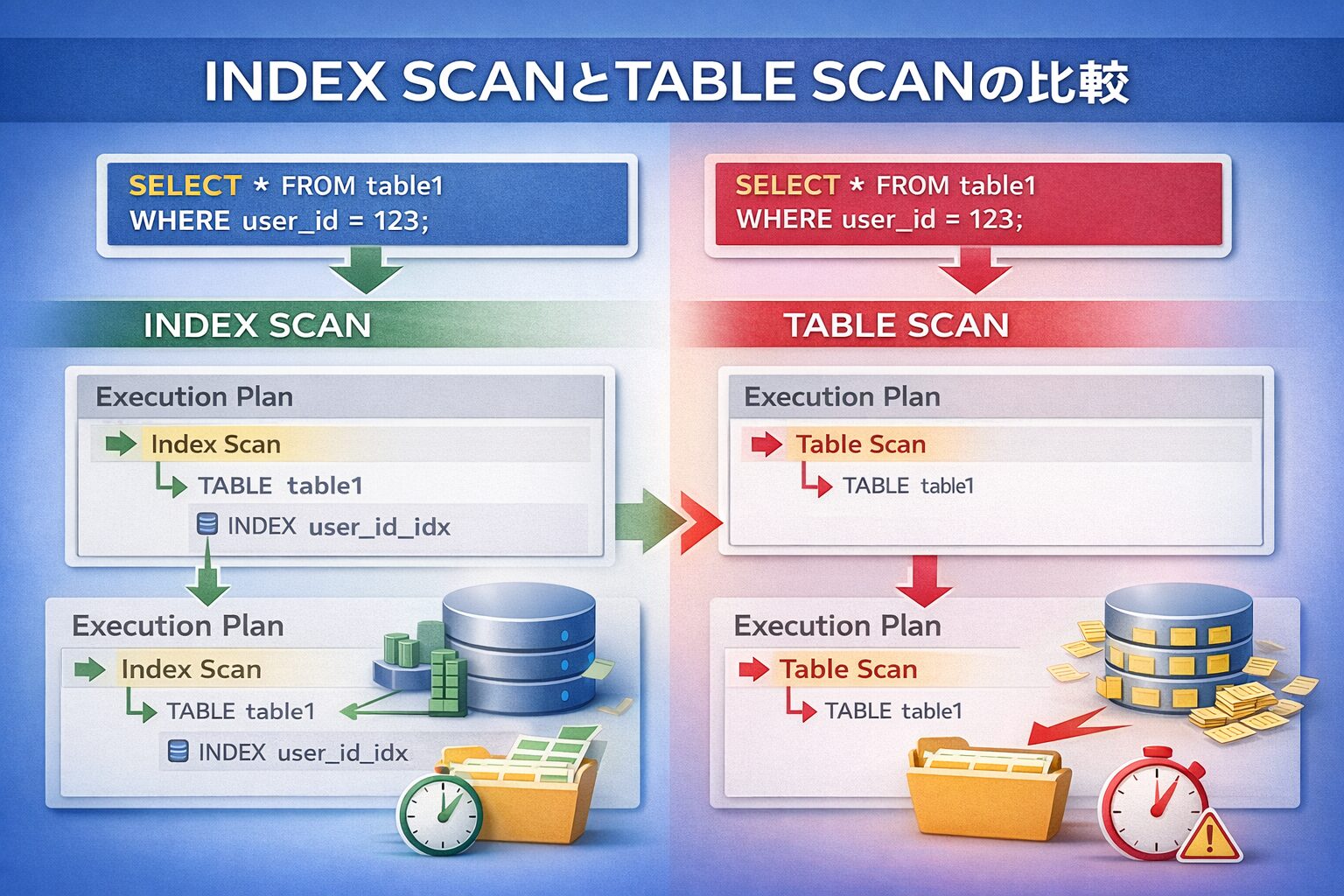
SQLのチューニングでは、INDEXが使われているかどうかを判断するために、実行計画の確認が欠かせません。
実行計画(EXPLAIN PLAN)の基本的な読み方や、処理が遅くなる原因となるボトルネックの見つけ方については、以下の記事で詳しく解説しています。
よくある質問|INDEXが効かない時の疑問まとめ
- INDEXがあるのに必ずフルスキャンになるのはなぜですか?
-
LIKE検索の書き方、列への関数適用、暗黙的な型変換などにより、INDEXが利用できない状態になっている可能性があります。
- LIKE検索は必ずINDEXが使えないのですか?
-
前方一致(’文字列%’)であれば、INDEXが使われる可能性があります。先頭に%がある場合は基本的に使われません。
- 関数を使うと必ずINDEXは無効になりますか?
-
列側に関数を適用した場合は無効になるケースが多いです。条件値側を加工する形に書き換えることで回避できます。
- 暗黙的変換はエラーにならないので問題ないのでは?
-
動作上は問題ありませんが、INDEXが効かなくなり、パフォーマンス低下の原因になります。
- 実行計画は毎回確認すべきですか?
-
はい。特に本番環境で使用するSQLは、必ず実行計画を確認することをおすすめします。
- OR条件を使った複数条件の検索でもインデックスは効きますか?
-
一般に、
WHERE col1 = ? OR col2 = ?のように OR条件で複数カラムを結合した検索 では、各カラムにインデックスが存在していてもオプティマイザがうまくインデックスを活用できず、フルテーブルスキャンになってしまうことが多いです。これはOR条件の性質上、どちらの条件で先に絞り込むべきか判断しにくいためで、SQL Server など多くのDBではこのケースは最適化されません。対策としては、条件を分けてUNIONで結合する、適切な複合インデックスを検討する、といった方法があります。 - インデックスがあるのに実行計画がテーブルスキャンになっている場合、他にも原因はありますか?
-
はい。インデックスが存在しても、実行計画上で インデックスが使われない(テーブルスキャンになる)理由 は他にもあります。例としては以下のようなケースです:
- 統計情報が古い場合:DBは統計情報を使って最適な実行計画を決めます。統計が古いとインデックスの有効性を適切に評価できず、誤ってテーブルスキャンを選ぶことがあります。
- テーブルが非常に小さい場合:行数が少ないと、オプティマイザがインデックスよりも フルスキャンの方が高速 と判断することがあります。
- SELECT * のように全カラムを取得する場合:インデックスだけで必要なデータを満たせないと、結局テーブル本体アクセスが必要になり、インデックスを使わない計画が選ばれることがあります。
まとめ
INDEXが効かない原因の多くは、SQLの書き方にあります。
LIKE検索、関数の使用、暗黙的な型変換は、いずれも意識せずに使ってしまいがちな要素です。
・列を加工しない
・データ型を正しく合わせる
・INDEXの特性を理解する
これらを意識することで、SQLのパフォーマンスは大きく改善します。

")
