



SQLで前方一致・後方一致・部分一致等のあいまい検索の方法についてご紹介します。
SQLであいまい検索を行う場合はワイルドカード文字として「%」を使用します。
サンプルテーブル
以下の商品テーブル「goods」を元に説明します。

前方一致検索
SQL文(クエリー)
-
- 前方一致検索する場合、LIKE演算子を指定して検索条件の最後に「%」を記載します。
- 「SELECT * FROM [テーブル名] WHERE LIKE ‘[条件]%’;」の形式で記述します。
|
1 |
SELECT * FROM goods WHERE name LIKE '商品%'; |
実行結果
以下の様に前方に「商品」と入力されているデータのみ出力されます。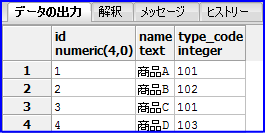
後方一致検索
SQL文(クエリー)
-
- 後方一致検索する場合、LIKE演算子を指定して検索条件の先頭に「%」を記載します。
- 「SELECT * FROM [テーブル名] WHERE LIKE ‘%[条件]’;」の形式で記述します。
|
1 |
SELECT * FROM goods WHERE name LIKE '%A'; |
実行結果
以下の様に後方に「A」と入力されているデータのみ出力されます。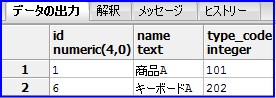
部分一致検索
SQL文(クエリー)
-
- 部分一致検索する場合、LIKE演算子を指定して検索条件の前後に「%」を記載します。
- 「SELECT * FROM [テーブル名] WHERE LIKE ‘%[条件]%’;」の形式で記述します。
|
1 |
SELECT * FROM goods WHERE name LIKE '%ボード%'; |
実行結果
以下の様に文字列に「ボード」が含まれているデータが出力されます。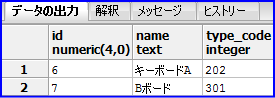
補足:実務で気をつけたいポイント & 応用例
1. ワイルドカード検索とインデックスの相性
LIKE 演算子を使ったあいまい検索は、通常のインデックスが利かないケースが多く、パフォーマンス低下の原因になります。
-
前方一致(
'文字列%')であれば B-Tree インデックスが使われることもありますが、後方一致('%文字列')や部分一致('%文字列%')では使われないことが多いです。 -
大量データを扱う場合は、全文検索エンジン(たとえば PostgreSQL の
pg_trgm拡張、Elasticsearch、MySQL の全文検索機能など)の導入を検討したほうがよいでしょう。
2. 大文字・小文字の扱い
データベースによっては、LIKE は大文字・小文字を区別するかどうかが異なります。
-
MySQL(
latin1やutf8_general_ciなど)では大文字・小文字を区別しないことが多い -
PostgreSQL では
ILIKEを使うことで大文字・小文字を無視したマッチングが可能 -
必要であれば、
LOWER()を併用して検索キーとカラムを小文字化して比較する方法もあります。
3. エスケープ処理
検索文字列中にワイルドカード文字(% や _)を含めたい場合は、適切にエスケープを行わないと意図しないマッチングをしてしまいます。SQL では ESCAPE 句を使ったり、特殊文字をエスケープ文字で前置したりする必要があります。
この例では「50%」という文字列を検索対象に含めたい場合の書き方です。
4. 複数条件との組み合わせ
あいまい検索と他の条件(数値比較、日付範囲、結合など)を組み合わせる際は、WHERE 句の書き方、実行計画、インデックス設計に注意が必要です。
たとえば、部分一致検索を先にするとスキャンが広くなり、結合条件や他の絞り込み条件を後に書いても性能が出にくくなる場合があります。
そのため、可能な限り絞り込み条件(等価比較や範囲条件など)を先に適用する、あるいはサブクエリ・CTE を使って事前に対象を絞るなど工夫するとよいでしょう。
5. 応用例:あいまい検索の代替アプローチ
| アプローチ | 用途・メリット | 注意点 |
|---|---|---|
| 正規表現検索(REGEXP、~ など) | より複雑なパターンマッチングが可能になる | パフォーマンスに注意、サポート状況に依存 |
| トークン分割・前処理 | 検索対象をあらかじめトークン化して部分一致を高速化 | 実装が複雑、追加のメンテナンスコストあり |
| 専用全文検索エンジン | 高速な全文検索、スコア付け、複合検索 | データ同期や運用コストを考慮 |
| n-gram / trigram 検索 | 部分一致の高速化を狙える技術 | インデックス設計やメモリ・ストレージ消費に注意 |