はじめに
企業間やシステム間のデータ連携でよく利用されるファイル転送ソフトウェア「HULFT」。日常的にCSVやログファイルをやり取りしている方も多いと思います。
その際に必ず出てくるのが「ファイルモードの指定」。HULFTには 「テキスト指定(レコード指定)」 と 「バイナリ指定」 の2種類があり、どちらを使うべきか迷うケースが少なくありません。
本記事では 「CSVをバイナリ指定で送った場合どうなるのか?」 を中心に、メリット・デメリットや注意点を整理します。
バイナリ指定とは?
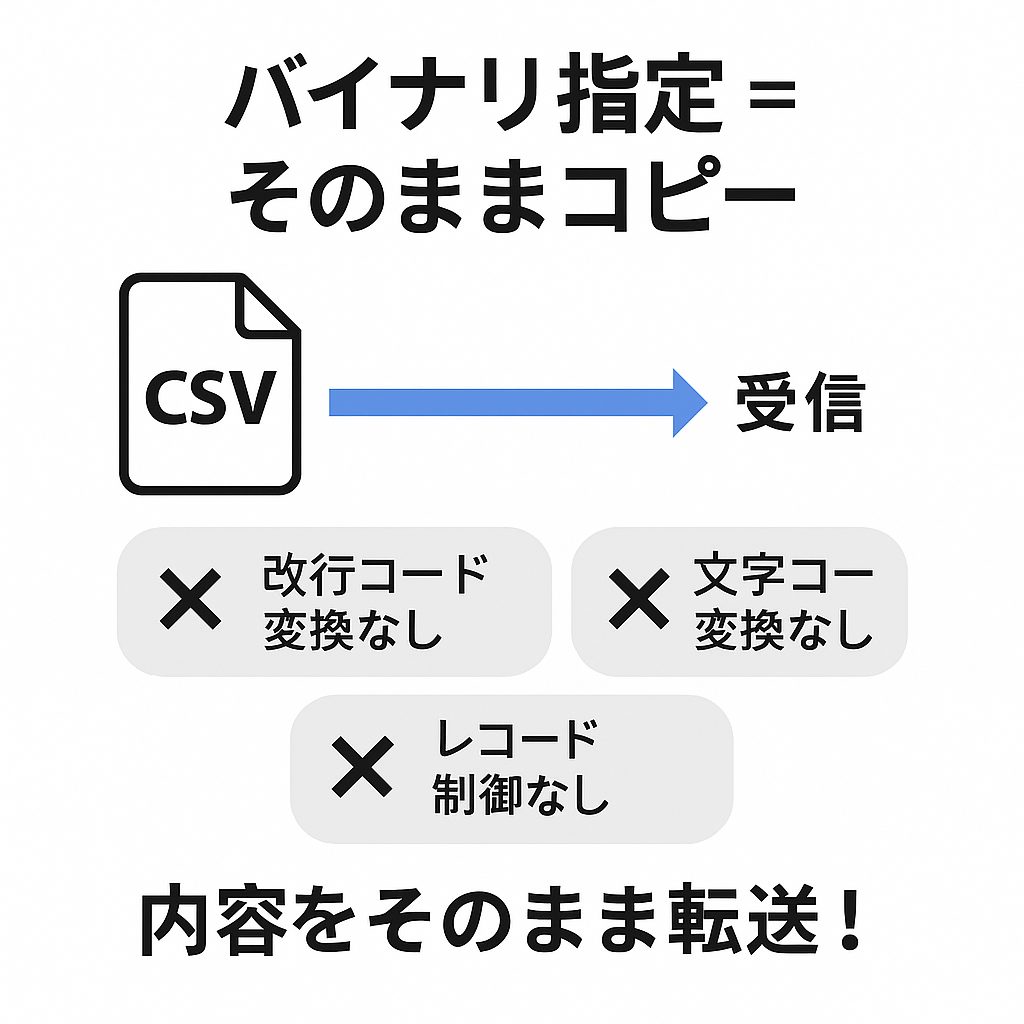
HULFTにおける「バイナリ指定」とは、ファイル内容を1バイト単位のデータとしてそのまま送受信するモードを指します。
この場合、HULFTは以下のような変換や処理を一切行いません。
-
改行コードの変換(CRLF⇔LFなど)
-
文字コードの変換(Shift-JIS⇔UTF-8など)
-
レコード単位の制御(固定長・可変長)
つまり「HULFTが何も手を加えずにコピーする」のがバイナリ指定です。
バイナリ指定のメリット
-
内容がそのまま届く
改行コードや文字コードが勝手に変換されないため、送信元のデータを完全に保持できます。 -
ファイル形式を問わない
CSVに限らず、Excel、PDF、ZIP、画像ファイルなども問題なく転送可能。
→ そのため「とりあえず壊れたくないファイルはバイナリ指定」で安全に扱えます。 -
異なるOS間でも安心
WindowsからLinux、Linuxからホスト系など、環境差異を気にせず転送できます。
バイナリ指定のデメリット
-
文字コード変換がされない
送信側がShift-JIS、受信側がUTF-8を前提としている場合、そのままでは文字化けします。 -
改行コードもそのまま
WindowsのCSV(CRLF)をLinuxで処理すると、アプリ側がLFを期待していた場合に不具合の原因になります。 -
レコード単位の扱いができない
COBOLやホストシステム連携など「固定長レコード前提」のファイルを扱う場合は不向きです。
CSVをバイナリ指定で送るとどうなる?
結論から言うと、基本的に悪影響はありません。
CSVは単なるテキストファイルですが、HULFT側で勝手に改行コードや文字コードを変換しないので、送信元と全く同じファイルが届きます。
ただし以下のケースでは注意が必要です。
-
文字コードが異なる場合
送信元がShift-JIS、受信先がUTF-8で解析 → 文字化けの可能性あり。 -
改行コードが異なる場合
Windowsで作成したCSVをLinuxで使うと、改行が意図通りに扱えないことがある。
そのため「受信側のシステムがどの文字コード・改行コードを想定しているか」を事前に確認しておくことが大切です。
まとめ
-
バイナリ指定は「ファイルをそのまま送りたいとき」に有効。
-
CSVを送る場合も基本的に問題はないが、受信側の文字コードや改行コードの前提条件によっては注意が必要。
-
迷ったらまずは「バイナリ指定」で送り、必要に応じて受信側で変換処理を入れるのが無難です。
👉 実際の業務では「相手先がどんなシステムで受けるのか」を確認してから指定するのが鉄則です。
もし「文字コード変換が必要」や「固定長レコード前提」のような要件がある場合は、バイナリ指定ではなくテキスト指定を選ぶ方が安全です。