



前回の記事
「🧠Pythonで学ぶ画像認識入門:TensorFlowとKerasで手書き数字を判定する方法(1) ~環境構築編~」
では、
「Python公式版+仮想環境を使ったTensorFlow開発環境構築」
を行い、AI開発の準備が整いました。
今回はその続編として、
実際にTensorFlowとKerasを使って手書き数字を判定するAIモデルを作る実践編 を解説します。
データの読み込みからモデルの学習・評価・予測までを、
最小限のシンプルなコードで体験してみましょう。
🧩 動作環境(前回と同じ構成)
🧠 ステップ①:MNISTデータセットを読み込む
TensorFlowには「手書き数字データ(MNIST)」が標準で付属しています👇
🧩 ステップ②:データの前処理
🧩 ステップ③:モデル構築(Keras Sequential)
🧩 ステップ④:学習を実行
🧩 ステップ⑤:テストデータで評価
🧩 ステップ⑥:実際に予測してみる
ステップ①~⑥のコードについて
各ステップは、順番に実行される処理の流れを分けて説明しているだけで、
実際のプログラムとしては 連続して動く1つのコード になります。
つまり、実際に実行する場合は次のようにすべてまとめて書いて問題ありません👇
✅ 例:mnist_sample.py として保存する内容
💾 保存と実行
-
C:\python_envなどに上記を mnist_sample.py として保存 -
仮想環境を有効化:
-
実行:
- 実行例
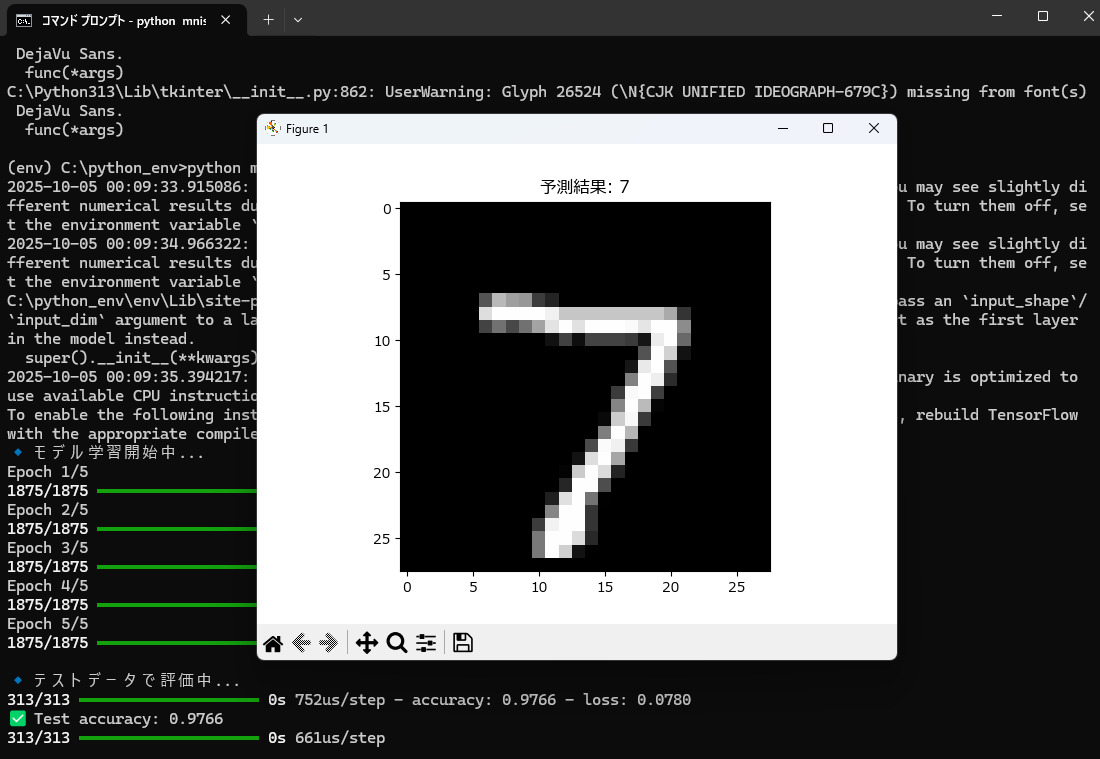
📊 補足:精度向上のヒント
-
CNN(畳み込みニューラルネットワーク) を導入する
-
Dropout で過学習を防止
-
エポック数や学習率 の調整
これらを追加すると、より実践的なモデルになります。
🚀 まとめ
本記事では、
TensorFlowとKerasを用いて「手書き数字判定AI」を実装しました。
これで、
-
データの前処理
-
モデル構築
-
学習・評価・予測
というAIの基本的な流れを一通り理解できたはずです。
次回
「🧠 Pythonで学ぶ画像認識入門:TensorFlowとKerasで手書き数字を判定する方法(3) ~CNNによる高精度モデル編~」
は、CNNを用いた高精度モデル化(第3回) に挑戦します🔥
「🧠 Pythonで学ぶ画像認識入門:TensorFlowとKerasで手書き数字を判定する方法(2) ~実践サンプルコード編~」への1件のフィードバック