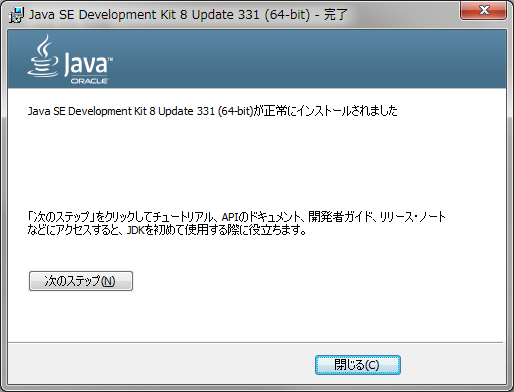
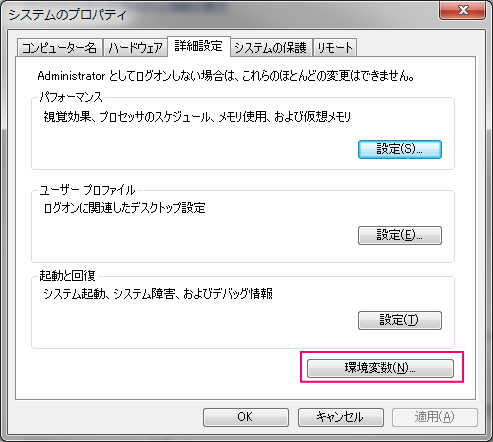
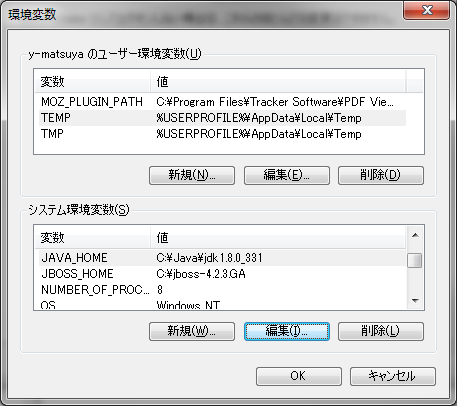
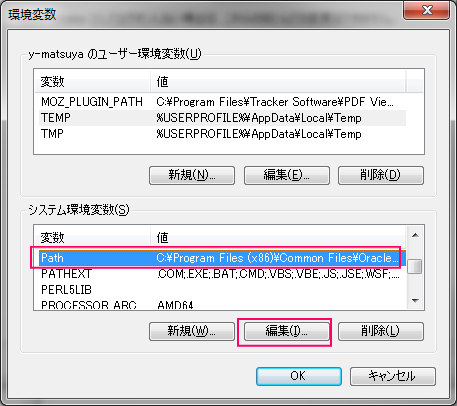
Java開発におけるログ出力は、障害解析・性能改善・監査の三種の神器。長年使われてきた log4j 1.x に対し、後継の log4j2 は「高速・柔軟・安全」に大幅進化しています。本稿では、違いが直感的に分かる比較と、**失敗しない導入手順(Maven/Gradle、設定、非同期化、移行の落とし穴まで)**をまとめます。
1. log4j 1.x と log4j2 の要点比較
| 観点 | log4j 1.x | log4j2 |
| パフォーマンス | 同期中心。大量ログでアプリに負荷 | LMAX Disruptorによる非同期ロガーで高速・低レイテンシ |
| 設定形式 | properties / XML のみ | XML / JSON / YAML / properties、ホットリロード対応 |
| 非同期化 | AsyncAppenderのみ | AsyncAppender+Async Logger(全ロガー非同期も可) |
| GC負荷 | 文字列連結が発生しやすくGC負担増 | 遅延評価(ラムダ/プレースホルダ)で不要時は連結処理なし |
| 拡張性 | 限定的 | フィルタ / レイアウト / Appender が豊富(JSON出力、Failover等) |
| メンテナンス | EoL(保守終了) | 現行バージョン維持(常に最新2.xを推奨) |
結論:高負荷・可観測性重視の現場ほど log4j2 一択。
2. こんな場面で「log4j2」を選ぶ
-
大量ログ(秒間1000件~万件)を裁くWeb/バッチ、IoT、決済、EC
-
本番でログレベルを動的変更したい(再起動なしで即調査)
-
JSON出力で Elasticsearch / OpenSearch / Splunk / Datadog に流す
-
遅延評価や MDC(相関ID) で可観測性とパフォーマンスを両立したい
3. 導入手順(Maven/Gradle)――最短で“動く”まで
ここでは log4j2 を実装(Core)として使い、APIは SLF4J で書く構成を推奨します。
理由:ライブラリ間の共通言語として SLF4J がデファクト、実装差し替えも容易。
3.1 依存関係を追加
Maven(pom.xml)
Gradle(Kotlin DSL)
重要:既存で引き込まれる logback-classic や slf4j-log4j12 は除外してください(重複実装エラー&二重出力の原因)。
3.2 旧実装の衝突を避ける(例:Maven の除外)
3.3 最小構成の設定ファイル(src/main/resources/log4j2.xml)
3.4 SLF4J での利用コード
3.5 ローリングファイル+JSON(実戦向け)
3.6 非同期化の推奨設定(高スループット向け)
方法A:Async Appender(部分的に非同期)
方法B:Async Logger(全ロガーを非同期化)
-
依存に disruptor を追加(前述)
-
JVM 起動オプションに以下を付与
|
|
-DLog4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector |
目安:秒間数千件以上のログ、遅延許容な処理では Async Logger が強力。
低遅延の必要なクリティカル処理(トランザクション境界直前など)は同期Appenderで分離も可。
3.7 現場で必須の“相関ID”(MDC/ThreadContext)
3.8 動的なログレベル変更(コード&設定)
3.9 他フレームワークのログを一本化(任意)
4. 旧 log4j 1.x からの移行チェックリスト
-
jar の置換と衝突解消
-
1.x の log4j-1.2.x.jar を除去
-
log4j-api, log4j-core, log4j-slf4j2-impl を追加
-
他実装(logback 等)を除外
-
設定ファイルを置き換え
-
コードの修正方針(推奨順)
-
SLF4J API へ書き換え(LoggerFactory.getLogger 等)
-
もしくは log4j2 API へ(org.apache.logging.log4j.LogManager.getLogger)
-
当面の暫定策として log4j-1.2-api(互換レイヤ)もあるが恒久利用は非推奨
-
性能と出力の検証
-
運用監視
5. 開発・運用の実用Tips
-
重い toString() を直接連結しない:log.debug("x={}", () -> obj.heavyToString())
-
Failover Appender で出力先障害に備える(ネットワークストレージ等)
-
パターン設計:時刻、レベル、ロガー、メッセージ、%throwable、MDC を最低限
-
本番では INFO 以上、詳細調査時のみ一時的に DEBUG/TRACE を開ける
-
最新 2.x 系を採用(セキュリティ修正が継続されるため)
6. まとめ
-
log4j2 は “高速+柔軟+安全”。大量ログ・可観測性要件に強い。
-
導入は依存追加 → 設定作成 → 非同期化の3ステップが核。
-
移行は衝突除去と設定変換が肝。SLF4J API で書くと将来の実装差し替えも容易。

HULFTには「送受信ジョブを定義して使う方法」以外に、utlsendなどのユーティリティ系コマンドを直接呼び出してファイル転送や加工を行う手段があります。
これらは事前の送受信定義が不要で、コマンド実行時に条件を指定できるため、テスト送信・スポット利用・簡易処理に非常に便利です。
本記事では、JavaでHULFTコマンドを実行する例をご紹介します。
-
utlsend : ファイル送信
-
utlrecv : ファイル受信
-
utlconcat : ファイル連結
-
utlsplit : ファイル分割
Javaから外部コマンドを実行する基本
Javaでは ProcessBuilder を使うことで、外部のHULFTコマンドを呼び出せます。
エラー出力も標準出力にまとめる設定をすれば、ログ管理が容易になります。
共通の呼び出しテンプレートは以下の通りです。
1. ファイル送信(utlsend)
事前の送信定義が不要で、対象ファイルと宛先ノードを直接指定できます。
-
-f : 送信するファイルパス
-
-n : 宛先ノード名(HULFTに登録済み)
2. ファイル受信(utlrecv)
受信ジョブを登録せず、コマンドだけでファイルを取得できます。
-
-f : 保存先のファイル名
-
-n : 送信元ノード名
3. ファイル連結(utlconcat)
複数のファイルを1つにまとめたいときに使います。
|
|
public class ExampleConcat { public static void main(String[] args) { HulftCommandRunner.runCommand( "utlconcat", "-o", "/data/merged.txt", "-f", "/data/file1.txt", "-f", "/data/file2.txt" ); } } |
-
-o : 出力ファイル名
-
-f : 結合対象のファイル(複数指定可)
4. ファイル分割(utlsplit)
大きなファイルを分割して処理したいときに使います。
-
-f : 分割対象ファイル
-
-l : 分割する行数(例:1000行ごと)
運用上の注意点
-
PATHの設定
Javaから呼び出す際は、utlsend.exe などのHULFTバイナリがPATHに通っている必要があります。
通っていない場合はフルパス指定が必須です。
-
終了コードの確認
-
ログ管理
実際の業務バッチでは process.getInputStream() の内容をファイル出力してログ管理することを推奨します。
まとめ
-
utlsend でファイルを即送信できる
-
utlrecv で即時受信が可能
-
utlconcat でファイルを連結
-
utlsplit でファイルを分解
これらをJavaから呼び出すことで、柔軟なファイル連携や加工処理が実現できます。
GCとは何か
Java で開発をしていると、よく耳にする「GC(Garbage Collection)」。
これは 不要になったオブジェクトを自動で回収してメモリを解放する仕組み のことです。C言語のように手動で free() を呼ぶ必要はなく、Java VM が裏側でメモリ管理を行います。
ざっくり構造・最近のGC
-
世代別回収:Eden/Survivor(若世代)→ Old(老世代)
-
Minor GC:Edenが埋まったら短命オブジェクト中心に回収
-
Major/Full GC:Oldが逼迫、断片化、クラス/メタ領域逼迫などで広域回収
-
既定GC:G1GC(Java 9+)。低停止要求は ZGC / Shenandoah も選択肢
主なトリガ
“悪い例 → 良い例”で学ぶメモリ/GC対策
1) 無制限キャッシュ(静的Map地獄)
悪い例
ポイント:上限なしは必ずOldを膨らませる。キャッシュは 容量・期限・エビクションを設計。
2) リスナ/コールバック未解除
悪い例
3) ThreadLocal の放置(プールスレッドに張り付く)
悪い例
良い例(finallyで確実に除去)
4) System.gc() 乱用
悪い例
5) ラムダ/内部クラスが外側(巨大オブジェクト)をキャプチャ
悪い例
良い例(必要最小限のデータだけ渡す・static化)
ポイント:キャプチャ=保持。意図せず大物を延命していないか疑う。
6) ループ内の大量一時オブジェクト
悪い例
良い例(StringBuilder再利用・ボクシング回避)
7) finalize/Cleaner頼み(遅延・不確実)
悪い例
8) クラスローダ・アプリ再デプロイ時のリーク
悪い例
良い例(クラスローダ境界を越える参照を断つ)
9) 巨大配列・Humongous割当ての長期保持(G1)
悪い例
良い例(分割・ストリーミング・寿命短縮)
ポイント:巨大ブロックは断片化と回収コスト増の温床。
10) 無制限のキュー/バッファ
悪い例
良い例(有界+バックプレッシャ)
GCログ・計測の始め方(JDK 9+)
-
まずはコードの割当て削減 → その後にヒープ/GC調整
-
監視:jcmd <pid> GC.heap_info / jstat -gc <pid> 1000
-
ボトルネック特定:JFR(Java Flight Recorder) で割当てホットスポットを把握
-
必要なら ZGC/Shenandoah も評価(レイテンシ目標に応じて)
実務チェックリスト(配布推奨)
-
System.gc() を禁止/抑制
-
キャッシュ・キューは有界+期限
-
ThreadLocal は finally で remove
-
リスナ/コールバックは確実に解除(AutoCloseable化が効く)
-
ループ内の一時オブジェクトを減らす(Builder再利用/ボクシング回避)
-
巨大配列は分割・短命化
-
クラスローダ境界を跨ぐ静的参照禁止、Executor停止・ドライバ解除
-
try-with-resourcesでオフヒープ即時解放
-
GCログ/JFRで事実ベースに調整
-
目標停止時間(例:MaxGCPauseMillis)を定めて検証
まとめ
GCは“自動”でも“万能”ではありません。
「GCが働きやすいコード」(不要参照を残さない・波及して大物を掴ませない・ピークメモリを避ける)を心がけ、ログ/計測で改善ループを回すのが最短距離です。



Webシステムは基本的に複数人で同時利用されるのが前提のため、マルチスレッドアクセスを考慮した設計・実装を行う必要があります。業務でJavaの各変数とスレッドセーフについて考える機会があったので、「インスタンス変数とローカル変数の違いとスレッドセーフとの関係」について今回は整理してみようと思います。
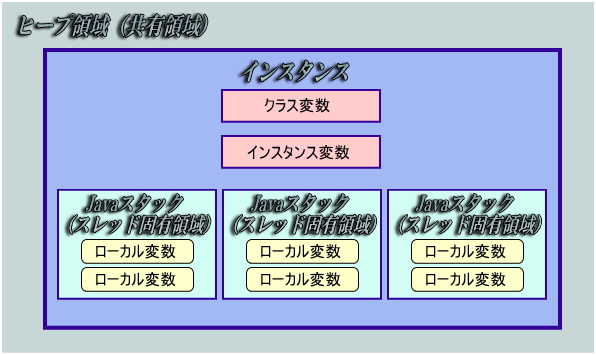
Javaでの変数毎のメモリ管理イメージ

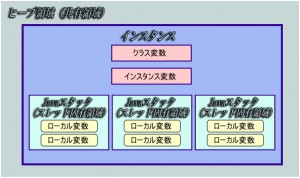
上記は変数毎のメモリ管理イメージとなります。Javaではクラス変数やインスタンス変数はヒープ領域と呼ばれる共有メモリ領域へ保存されます。複数のスレッドで共有され別のスレッドに書き換えられる可能性があり,スレッドセーフではありません。対してローカル変数はJavaスタックと呼ばれるスレッド固有メモリ領域へ保存されます。スレッド固有領域なので別のスレッドに書き換えられる可能性はないのでスレッドセーフとなります。
インスタンス変数とは
- サンプルコード
|
|
public class ClassSample{ /** インスタンス変数 */ private String hoge; } |
- メソッドの外に記述します。staticは付けません(staticが付くとクラス変数になります)。
- ヒープ領域と呼ばれる共有メモリ領域へ保存される為、宣言しただけではスレッドセーフにはなりません。
- スレッドセーフを保つ為には初期化する必要があります。
- コンスラクタで初期化
- インスタンス宣言時に初期化
- 最初のget時に初期化
- 他のスレッドからの更新を防ぐ為、修飾子はprivateにする必要があります。
- 当該クラス内の任意のメソッドから参照可能となります。
ローカル変数とは
- サンプルコード
|
|
public class ClassSample{ public static void methodSample(){ // ローカル変数 int num = 1; } } |
- メソッド内に記述します。
- そのメソッドが実行中の間だけ有効となります。
- Javaスタックと呼ばれるスレッド固有メモリ領域へ保存される為、スレッドセーフとなります。
「駑馬十駕」を信念に IT系情報を中心に調べた事をコツコツ綴っています。