SQLで最大値と最小値を求めるにはMAX関数とMIN関数を使用します。
使用例
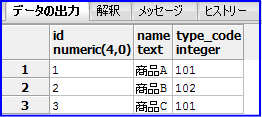
- サンプルテーブル「goods」
- クエリー(SQL)
サンプルテーブル「goods」のtype_codeの最大値と最小値を抽出しているサンプルとなります。
1SELECT MAX(type_code), MIN(type_code) FROM goods; - 出力結果


SQL関連のカテゴリ
SQLで最大値と最小値を求めるにはMAX関数とMIN関数を使用します。
サンプルテーブル「goods」のtype_codeの最大値と最小値を抽出しているサンプルとなります。
|
1 |
SELECT MAX(type_code), MIN(type_code) FROM goods; |
IN句をEXISTS句へ変換するとパフォーマンスが向上すると言われることがあるので
IN句からEXISTS句への変換例をメモしておきます。
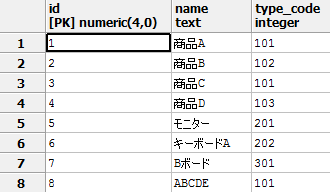
以下の商品テーブル「goods」と属性コードテーブル「type_code」を元に説明します。
商品テーブル「goods」のtype_codeが ‘101’で属性コードテーブル「type_code」にも存在する商品名を取得する例となります。
|
1 2 3 4 |
SELECT tc.code_name FROM type_code AS tc WHERE tc.code IN(SELECT type_code FROM goods WHERE type_code = '101'); |
WHERE句後の「tc.code IN」を「EXISTS」に変更し、「AND type_code = tc.code」を追加しただけです。
|
1 2 3 4 5 |
SELECT tc.code_name FROM type_code AS tc WHERE EXISTS (SELECT 1 FROM goods WHERE type_code = '101' AND type_code = tc.code); |
IN句、EXISTS句どちらの場合も以下の結果となります。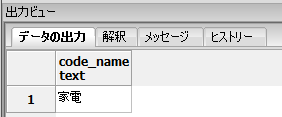
EXISTS句は使い慣れてないと今一つ分かりにくい気がするので、上記のEXISTSをNOT EXISTSで実行してみた例も記載しておきます。なんとなくEXISTSがどういう結果を出力しているかわかるかも。。
|
1 2 3 4 |
SELECT tc.code_name FROM type_code AS tc WHERE NOT EXISTS(SELECT 1 FROM goods WHERE type_code = '101' AND type_code = tc.code); |
NOT EXISTS句の結果は以下となります。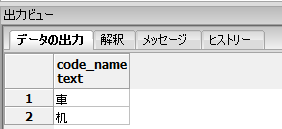
本稿では、 IN句 から EXISTS句 への変換例およびその基本的な使い分けを紹介しましたが、実運用においては以下の点にもご留意ください。
データベース製品(たとえば PostgreSQL/Oracle Database/MySQL)やバージョンによって、IN句とEXISTS句の内部実行プランや最適化状況が異なるため、単純に「INは遅い」「EXISTSの方が速い」と一律判断するのは危険です。
実際には、サブクエリの対象件数・インデックス構成・統計情報の鮮度などがパフォーマンスに大きく影響します。EXISTSに変えたからといって必ずしも高速化するとは限りません。
また、可読性・保守性の観点からは「どちらが読みやすいか・将来変更しやすいか」も考慮に入れるべきです。たとえば、複雑な条件・結合・集計を伴うSQLでは、意図が明確な記述を優先したほうがトラブルを防げます。
最後に、SQLのチューニングは「手段」ではなく「目的」—つまり、「実際の業務で期待されるレスポンスタイムを満たしているか」「運用負荷を適切にコントロールできているか」という観点が最も重要です。この点を忘れず、必要に応じて実行計画の確認やプロファイリングを実施してください。
引き続き、SQL設計・実装・運用の改善にお役立ていただければ幸いです。
今後も他の観点(たとえば JOINの最適化/ウィンドウ関数の活用/データ量に対するスケーリング)についても、機会を改めてご紹介したいと思います。
SQLで指定した件数のみ取得する場合、MySQLやPostgreSQLではLIMIT句を使用します。
OracleではLIMIT句は使用できないのでROWNUMを使用します。
クエリーの最後にLIMIT(取得したいレコード数)を指定することで指定した件数のみ取得することが出来ます。
|
1 |
SELECT * FROM goods ORDER BY type_code LIMIT(3); |
Oracleの場合、ROWNUMを指定しただけではORDER BYでソート後の状態で取得ができないので副問合せで一度ソート後にROWNUMを指定することで指定した件数で取得することが出来ます。
|
1 2 3 |
SELECT * FROM (SELECT * FROM goods ORDER BY type_code) WHERE ROWNUM <= 3; |

SQLでGROUP BYとCOUNTを使用して重複行をカウントする方法です。
GROUP BYでカウントしたい列を指定し、COUNTでGROUP BYに指定した列を指定することで重複行のカウントが可能となります。
|
1 |
SELECT type_code,COUNT(type_code) FROM goods GROUP BY type_code; |
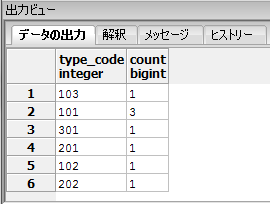
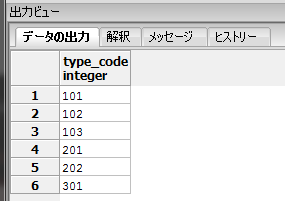
SQLでSELECT結果の重複行を削除するためにはDISTINCTを使用します。
SELECTの直後にDISTINCTを指定することで重複行を除外することが出来ます。
|
1 |
SELECT DISTINCT type_code FROM goods ORDER BY type_code; |
SQLで全角文字と半角文字を判定するにはLENGTHBやOCTET_LENGTH関数で取得したバイト数とLENGTH関数で取得した文字数を比較することで判断することができます。
ORACLEの場合はOCTET_LENGTHをLENGTHBへ変更すれば同様の結果を得られます。
|
1 2 3 4 |
SELECT SELECT name FROM goods WHERE name is NOT NULL AND LENGTH(name) <> OCTET_LENGTH(name); |

SQLでバイト数を取得する場合は、LENGTHBやOCTET_LENGTH関数を使用することで取得出来ます。
DBMS毎に使用できる関数が異なり、ORACLEではLENGTHB、MYSQLやPostgreSQLではOCTET_LENGTH、AccessではLENBが使用できます。
| DBMS | バイト数を取得できる関数 | 備考 |
|---|---|---|
| ORACLE | LENGTHB | ・全角文字の場合には使用しているキャラクタセットによりバイト数は異なる ※UTF-8 の場合には全角文字1文字が3バイト ・ CLOB と NCLOB において LENGTHB は使用できない |
| MYSQL or PostgreSQL | OCTET_LENGTH | |
| Access | LENB | |
| SQLServer | 対象なし |
|
1 |
SELECT name, OCTET_LENGTH(name) FROM goods; |
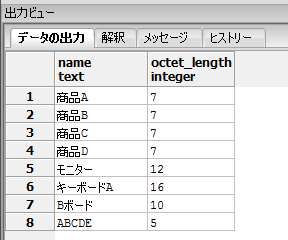
SQLで前方一致・後方一致・部分一致等のあいまい検索の方法についてご紹介します。
SQLであいまい検索を行う場合はワイルドカード文字として「%」を使用します。
以下の商品テーブル「goods」を元に説明します。

|
1 |
SELECT * FROM goods WHERE name LIKE '商品%'; |
以下の様に前方に「商品」と入力されているデータのみ出力されます。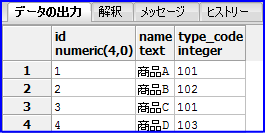
|
1 |
SELECT * FROM goods WHERE name LIKE '%A'; |
以下の様に後方に「A」と入力されているデータのみ出力されます。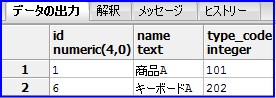
|
1 |
SELECT * FROM goods WHERE name LIKE '%ボード%'; |
以下の様に文字列に「ボード」が含まれているデータが出力されます。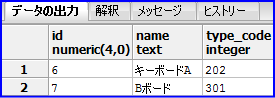
LIKE 演算子を使ったあいまい検索は、通常のインデックスが利かないケースが多く、パフォーマンス低下の原因になります。
前方一致('文字列%')であれば B-Tree インデックスが使われることもありますが、後方一致('%文字列')や部分一致('%文字列%')では使われないことが多いです。
大量データを扱う場合は、全文検索エンジン(たとえば PostgreSQL の pg_trgm 拡張、Elasticsearch、MySQL の全文検索機能など)の導入を検討したほうがよいでしょう。
データベースによっては、LIKE は大文字・小文字を区別するかどうかが異なります。
MySQL(latin1 や utf8_general_ci など)では大文字・小文字を区別しないことが多い
PostgreSQL では ILIKE を使うことで大文字・小文字を無視したマッチングが可能
必要であれば、LOWER() を併用して検索キーとカラムを小文字化して比較する方法もあります。
検索文字列中にワイルドカード文字(% や _)を含めたい場合は、適切にエスケープを行わないと意図しないマッチングをしてしまいます。SQL では ESCAPE 句を使ったり、特殊文字をエスケープ文字で前置したりする必要があります。
この例では「50%」という文字列を検索対象に含めたい場合の書き方です。
あいまい検索と他の条件(数値比較、日付範囲、結合など)を組み合わせる際は、WHERE 句の書き方、実行計画、インデックス設計に注意が必要です。
たとえば、部分一致検索を先にするとスキャンが広くなり、結合条件や他の絞り込み条件を後に書いても性能が出にくくなる場合があります。
そのため、可能な限り絞り込み条件(等価比較や範囲条件など)を先に適用する、あるいはサブクエリ・CTE を使って事前に対象を絞るなど工夫するとよいでしょう。
| アプローチ | 用途・メリット | 注意点 |
|---|---|---|
| 正規表現検索(REGEXP、~ など) | より複雑なパターンマッチングが可能になる | パフォーマンスに注意、サポート状況に依存 |
| トークン分割・前処理 | 検索対象をあらかじめトークン化して部分一致を高速化 | 実装が複雑、追加のメンテナンスコストあり |
| 専用全文検索エンジン | 高速な全文検索、スコア付け、複合検索 | データ同期や運用コストを考慮 |
| n-gram / trigram 検索 | 部分一致の高速化を狙える技術 | インデックス設計やメモリ・ストレージ消費に注意 |
業務でデータベースの操作をする場合、データが大量に登録されているテーブルへアクセスする場合に索引(INDEX)を作成するとSQLクエリの実行が劇的に早くなるケースが多々あります。この索引(INDEX)についてどういう場合に作成すれば良いのか、メリット、デメリット等についてまとめておきます。
SQLで1つの項目に対して複数の値に一致した条件で検索する方法をご紹介します。
この場合、考えられる方法としては「OR」演算子を使用する方法と「IN」演算子を使用する2つの方法があります。
通常はIN演算子で済むような条件であればOR演算子は使用しません。
「OR」演算子を使用する場合、以下の様にWHERE句にOR演算子を指定する事で複数の値で検索する事が出来ます。
「SELECT * FROM [テーブル名] WHERE [条件1] OR [条件2];」形式で記述します。
|
1 |
SELECT * FROM goods WHERE type_code = 101 OR type_code = 102; |
「IN」演算子を使用する場合、以下の様にWHERE句にIN演算子を指定する事で複数の値で検索する事が出来ます。
「SELECT * FROM [テーブル名] WHERE [列名] IN ([値1], [値2] …;」形式で記述します。
|
1 |
SELECT * FROM goods WHERE type_code IN(101, 102); |
「OR」演算子、「IN」演算子どちらで実行した場合も取得結果は以下の様になります。