oracleの独自関数としてNVL関数やNVL2関数があります。
知ってると結構便利な関数なので、この2つの関数の違いについて整理しておきます。
NVL関数とは
NVL関数は第1引数がNULLなら第2引数の値(代替値)を返します。
もし第1引数の結果がNULLでなければ、そのまま第1引数の値を返します。
注意点として第1引数と第2引数へは同じデータ型を指定する必要があります。
NVL関数の使用例
- サンプルテーブル「CLIENT_ADDRESS」

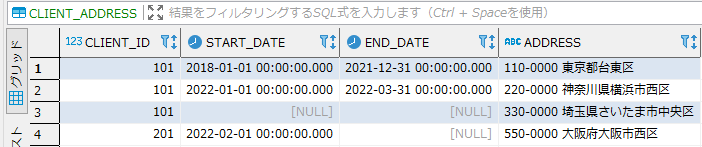
- SQL(クエリー)例
以下の例ではEND_DATEがNULLでない場合はEND_DATEの値を、NULLの場合はsysdateを返却します。
|
|
SELECT NVL(END_DATE, sysdate) FROM CLIENT_ADDRESS; |
- 実行結果

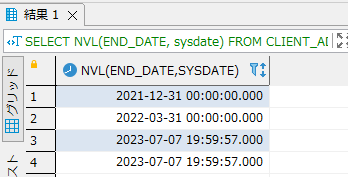
NVL2関数とは
NVL2関数は第1引数がNULLの場合に、第2引数の値を返却し、第1引数がNULLの場合は第3引数の値を返却します。
注意点として第1引数、第2引数、第3引数に指定する値は全て同じデータ型を指定する必要があります。
NVL2関数の使用例
- サンプルテーブル「CLIENT_ADDRESS」
- SQL(クエリー)例
以下の例ではEND_DATEがNULLでない場合は第2引数のSTART_DATEの値を返却し、END_DATEがNULLの場合は第3引数のsysdateを返却します。
|
|
SELECT NVL2(END_DATE, START_DATE, sysdate) FROM CLIENT_ADDRESS; |
- 実行結果

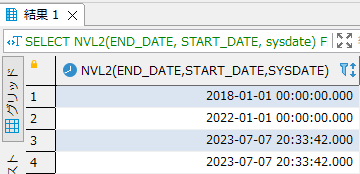
補足:実務での利用上の注意と代替案のご提案
Oracle の NVL/NVL2 関数は便利な反面、以下のような点に留意して使うとより安全・効率的です。
-
データ型制約に注意する
NVL/NVL2 では、引数に与える値が「同じデータ型」でなければなりません(Oracle の仕様)という制約があります。
たとえば、日付型と文字列型を混在させて使おうとすると、意図しない型変換やエラーを招く可能性があります。
-
NULL の扱いが複雑な場合には COALESCE の利用も検討する
複数の候補値を順番に評価して最初に NULL でないものを返すような処理をしたい場合は、NVL/NVL2 よりも COALESCE のほうが可読性・拡張性の面で優れるケースがあります。
たとえば、複数の列を順番にチェックして最初の非 NULL 値を採りたいときなどには COALESCE のほうが直感的に記述できます。
-
パフォーマンス面の配慮
NULL チェック・代替値の置き換えという処理自体は軽い操作ですが、複雑な SQL や大規模データセットで組み合わされると、意図せぬオーバーヘッドになることがあります。
特にインデックス条件や結合条件の中で使う場合は、実行プランを確認して予期せぬフルスキャンなどになっていないか注意しましょう。
-
意図の可視化
関数を多用するクエリは読みづらくなりがちです。
「なぜこの列で NULL チェックをするのか」「代替値にはなぜこの値を選んだか」といった背景を、コメントやドキュメントとして残しておくと、後から見直すときに助けになります。


性能試験などであるテーブルに大量データの作成が必要になった場合にINSERT文をループで処理できれば便利!という事で、SQLとロジックを組み合わせたストアドプロシージャでのサンプルプログラムとなります。
ストアドプロシージャ
|
|
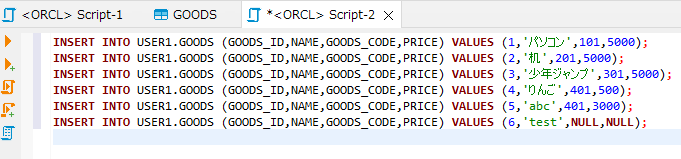
DECLARE -- 変数の宣言 counter NUMBER := 1; loop_limit NUMBER := 10; goods_id NUMBER := 1; BEGIN WHILE counter <= loop_limit LOOP -- 実行するSQL INSERT INTO USER1.GOODS (GOODS_ID,NAME,GOODS_CODE,PRICE) VALUES (goods_id,'パソコン',101,5000); -- インクリメント counter := counter + 1; -- カウンタをインクリメント goods_id := goods_id + 1; -- GOODS_IDをインクリメント END LOOP; -- 正常終了すれば自動的にCOMMITされるため明示的なCOMMITは不要。途中で失敗した場合は全件ロールバックされる -- DBクライアントソフトが自動コミットしない場合は明示的なCOMMITが必要 END; |
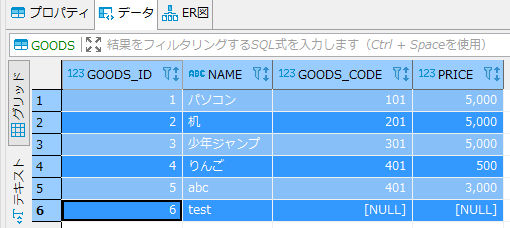
上記の例では、loop_limitに指定した件数分「GOODS」テーブルへレコードを追加するサンプルコードです。
上記の例では、loop_limitを10としていますが、必要に応じて任意の数値に変更できます。
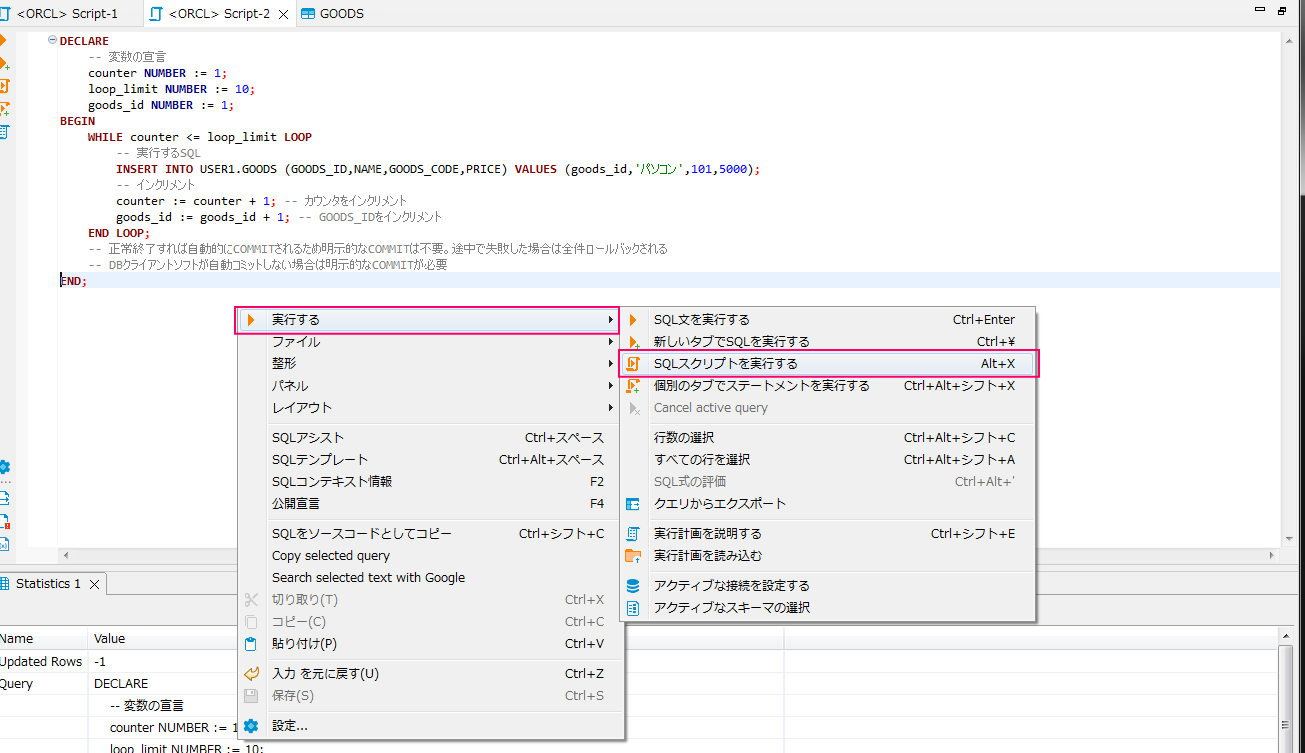
DBeaverで上記のストアドプロシージャを実行する場合は「SQLスクリプトを実行する」を選択することで正常に実行されます。

実行結果


SQLで単語の先頭1文字目のみ小文字から大文字へ変更したい場合は、INITCAP関数を使用することで可能となります。引数に変換したい文字を指定すればOKです。単語の区切りはスペースかアルファベット以外の文字(ハイフン「-」、カンマ「,」、アンダースコア「-」など)を区切り文字として見做して変換されます。
DBMS毎の使用可否
- 一般的な以下のDBMSではINITCAP関数は使用可能です。
サンプルテーブル
- 「GOODS」テーブル


INITCAP関数の使用例
SQL(クエリー)
|
|
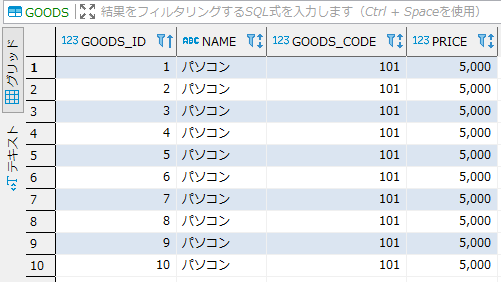
SELECT INITCAP(g.NAME) FROM GOODS g; |
実行結果
- 以下のように区切り文字の単語別に先頭文字が大文字に変換されているのが確認出来ます。

SQLで指定した日付項目(該当年月)の月末日を取得するには「LAST_DAY」関数を使用します。うるう年でも正確な月の最終日を取得出来ます。
DBMS毎の使用可否
- SQL Serverでは「EOMONTH」関数で最終日付を取得出来ます。
| 関数\DBMS | MySQL | PostgreSQL | SQL Server | Oracle |
| LAST_DAY | ○ | ○ | ✕ | ○ |
| EOMONTH | ✕ | ✕ | ○ | ✕ |
日付(該当月)の最終日を取得する例
サンプルテーブル「BIRTHDAY」


SQL(クエリー)
- BIRTHDAYテーブルの項目「BIRTHDAY」の最終日を取得する例となります。
|
|
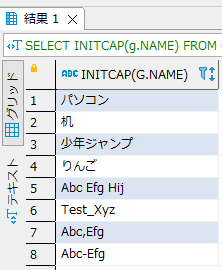
SELECT LAST_DAY(b.BIRTHDAY) FROM BIRTHDAY b |
実行結果


顧客の有効住所などを管理しているテーブルからある特定の日付時点で有効な住所を取得する方法をメモしておきます。
特定の日付時点で有効な住所情報を取得するサンプル
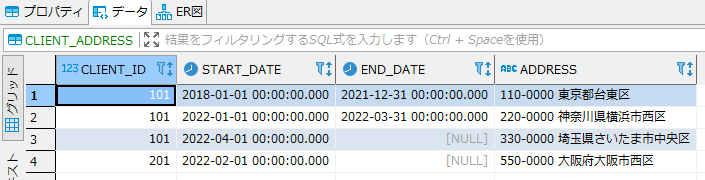
サンプルテーブル
- 「CLIENT_ADDRESS」テーブル
以下の様に顧客ID(CLIENT_ID)毎に有効な住所を管理するテーブルです。最新の住所のEND_DATEはnullとして管理してます。

クエリー(SQL)
- ‘2022-03-31’時点で有効な住所情報を取得する例です。
|
|
SELECT ca.* FROM CLIENT_ADDRESS ca WHERE TRUNC(ca.START_DATE) <= '2022-03-31' AND ('2022-03-31' <= TRUNC(ca.END_DATE) OR ca.END_DATE IS NULL); |
実行結果


SQLでは特定の項目の昇順、降順ではなく任意の順序で並べ替えて取得することも出来ます。
任意の順序でソートするにはORDER BY句でCASE文を指定する事で取得することが出来ます。
任意の順でソートする例
サンプルテーブル
「BIRTHDAY」テーブル
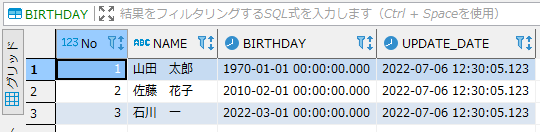
クエリー(SQL)
|
|
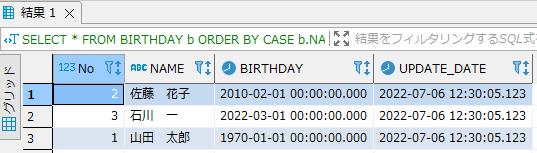
FROM BIRTHDAY b ORDER BY CASE b.NAME WHEN '佐藤 花子' THEN 1 WHEN '石川 一' THEN 2 WHEN '山田 太郎' THEN 3 END; |
出力結果

SQLでsysdateなどの日付型へ加算、減算してxx日後、xxヶ月後、xx年後を求める方法をメモしておきます。
xx秒後、xx秒前を求める方法
クエリー(SQL)例
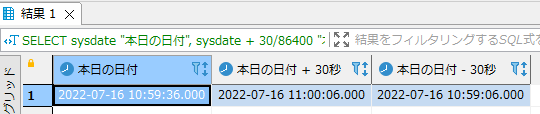
- システム日付の30秒後と30秒前を取得する例です。
|
|
SELECT sysdate "本日の日付", sysdate + 30/86400 "本日の日付 + 30秒", sysdate - 30/86400 "本日の日付 - 30秒" FROM dual; |
実行結果

xx分後、xx分前を求める方法
クエリー(SQL)例
- システム日付の5分後と5分前を取得する例です。
|
|
SELECT sysdate "本日の日付", sysdate + 5/1440 "本日の日付 + 5分", sysdate - 5/1440 "本日の日付 - 5分" FROM dual; |
実行結果

xx時間後、xx時間前を求める方法
クエリー(SQL)例
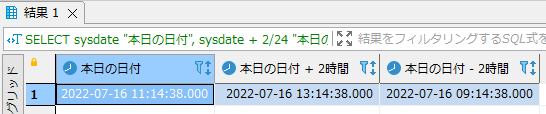
- システム日付の2時間後と2時間前を取得する例です。
|
|
SELECT sysdate "本日の日付", sysdate + 2/24 "本日の日付 + 2時間", sysdate - 2/24 "本日の日付 - 2時間" FROM dual; |
実行結果

xx日後、xx日前を求める方法
クエリー(SQL)例
- システム日付の1日後と1日前を取得する例です。
|
|
SELECT sysdate "本日の日付", TO_CHAR(sysdate + 1,'YYYY-MM-DD') "本日の日付 + 1日", TO_CHAR(sysdate - 1,'YYYY-MM-DD') "本日の日付 - 1日" FROM dual; |
実行結果

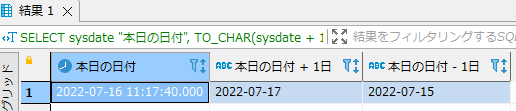
xxヶ月後、xxヶ月前を求める方法
クエリー(SQL)例
- システム日付の1ヶ月後と1ヶ月前を取得する例です。ADD_MONTHS関数は1/31の1ヶ月後は2/28となるように上手く月末日を調整してくれます。
|
|
SELECT sysdate "本日の日付", TO_CHAR(ADD_MONTHS(sysdate, 1),'YYYY-MM-DD') "本日の日付 + 1ヶ月", TO_CHAR(ADD_MONTHS(sysdate, -1),'YYYY-MM-DD') "本日の日付 - 1ヶ月" FROM dual; |
実行結果
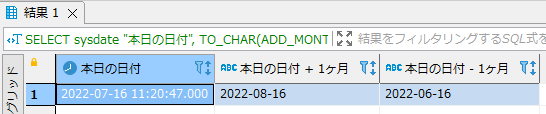
xx年後、xx年前を求める方法
クエリー(SQL)例
- システム日付の1年後と1年前を取得する例です。ADD_MONTHS関数に12の倍数を指定することで年単位での加減算が可能となります。
|
|
SELECT sysdate "本日の日付", TO_CHAR(ADD_MONTHS(sysdate, 12),'YYYY-MM-DD') "本日の日付 + 1年", TO_CHAR(ADD_MONTHS(sysdate, -12),'YYYY-MM-DD') "本日の日付 - 1年" FROM dual; |
実行結果

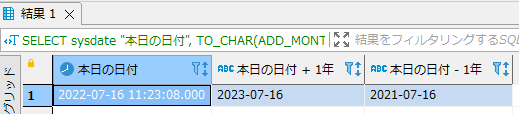
補足:他データベースでの日付加算と実務での注意点
本記事では Oracle を前提に日付演算を紹介しましたが、他の主要データベースでも「xx日後/xxヶ月後/xx年後」を取得する方法が存在します。移植性や比較の参考として以下に整理します。
| DBMS | 日数加算の例 | 月・年加算の例 |
| Oracle | SYSDATE + 3 | ADD_MONTHS(SYSDATE, 1)(1ヶ月後) / ADD_MONTHS(SYSDATE, 12)(1年後) |
| MySQL | DATE_ADD(NOW(), INTERVAL 3 DAY) | DATE_ADD(NOW(), INTERVAL 1 MONTH) / INTERVAL 1 YEAR |
| SQL Server | DATEADD(day, 3, GETDATE()) | DATEADD(month, 1, GETDATE()) |
| PostgreSQL | CURRENT_DATE + INTERVAL '3 day' | + INTERVAL '1 month' / '1 year' |
月末日の扱いについて注意
-
Oracle の ADD_MONTHS('2024-01-31', 1) → 2024-02-29(存在しない日付は月末に補正)
-
MySQLやPostgreSQL でも同様に月末補正される場合があります
-
契約更新日などで「きっちり同日を基準にしたい」場合は仕様確認が必要です
実務でよくある活用例
-
支払期限:請求日+30日
-
契約更新:契約開始日から6ヶ月後/1年後
-
リマインダー:イベント前7日/前1時間
-
登録日を基準としたステップメール通知
減算にも応用可能
📌 上記を踏まえると、「日付加算はDBごとに関数が異なる」「月末や閏年の補正挙動を理解しておく」という点を意識しておくと、より安全なSQL設計につながります。
Oracleでのセッションやプロセス数には上限があり、それを超えてしまうとデータベースにアクセス出来ずに予期せぬエラー(ORA-12519)が発生するなどの不具合が発生してしまいます。
Oracleで最大プロセス数や最大セッション数は初期化パラメータを管理しているSPFILEに定義されています。変更前にSPFILEのバックアップを取得しておくのをオススメします。
SPFILEの配置場所
Oracle DB 18cの場合の例です。
- 配置位置:[ORACLE_HOME]/database/SPFILE[ORACLE_SID].ORA
(例)C:\ORACLE\WINDOWS.X64_180000_db_home\database\SPFILEORCL.ORA
最大プロセス数、最大セッション数の変更方法
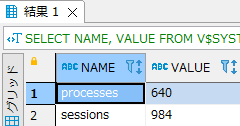
- 最初に「V$SYSTEM_PARAMETER」から現在の最大プロセス数と最大セッション数の設定値を確認します。「V$SYSTEM_PARAMETER」はインスタンスに現在有効になっている初期化パラメータ情報を示します。
|
|
SELECT NAME, VALUE FROM V$SYSTEM_PARAMETER WHERE NAME IN('processes', 'sessions'); |

- 次にALETER文でプロセス数の上限を変更します。
|
|
ALTER SYSTEM SET PROCESSES = 1000 SCOPE=SPFILE; |
- SPFILEの変更はOracleを再起動しないと適用されないため、Oracle DBを再起動します。
詳細は「Oracle Database(Oracleサーバ)の再起動(停止・起動)手順」参照
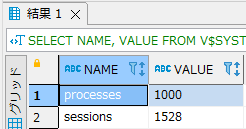
- 再度プロセス数とセッション数を確認すると上限が変更されているのが確認出来ます。セッション数は明示的に変更しなくてもプロセス数の変更に比例して上限が増えます。
|
|
SELECT NAME, VALUE FROM V$SYSTEM_PARAMETER WHERE NAME IN('processes', 'sessions'); |

補足
なお、今回ご紹介した Oracle Database における「最大プロセス数(PROCESSES)」および「最大セッション数(SESSIONS)」の変更手順については、環境や用途によって最適値が異なります。以下の点にご留意ください。
-
本番環境では、まずテスト環境で変更を検証したうえで適用することをおすすめします。変更後の再起動により影響が出る可能性があります。
-
PROCESSES の値を単に増やせば良いわけではなく、実際の接続数・負荷・リソース使用量を定期的にモニタリングする必要があります(例:V$SESSION、V$PROCESS、V$RESOURCE_LIMIT など)。
-
セッション数(SESSIONS)は PROCESSES の設定に影響を受けており、一般に「SESSIONS ≒ PROCESSES × 1.1〜1.2」のような目安が用いられますが、具体的には接続方式やアプリケーション構成によって変動します。
-
多数のプロセスを許容する設定にする際は、サーバーのメモリ・CPU・I/Oリソースに対する影響も併せて考慮する必要があります。負荷のピーク時にはリソース競合が起きやすくなります。
-
万一、変更前の値に戻す必要が生じた場合は、適用後のログやパフォーマンス指標を保持しておくことで、トラブルシューティングが容易になります。
以上を踏まえ、環境に適した値の設定および運用体制を整えたうえでパラメータ変更を実施して頂ければと思います。安心して運用を続けるための一助となれば幸いです。

SQLに慣れてない頃だとnullを判定する際は「xx = null」などと書いてしまいがちですが、SQLでNULLを判定するには「xx is null」 or 「xx is not null」と記載します。
使用例
サンプルテーブル
「GOODS」

NULLのデータを抽出する例
クエリー(SQL)
|
|
SELECT * FROM GOODS g WHERE GOODS_CODE IS NULL; |
実行結果


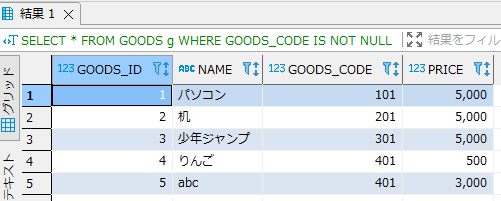
NULL以外のデータを抽出する例
クエリー(SQL)
|
|
SELECT * FROM GOODS g WHERE GOODS_CODE IS NOT NULL; |
実行結果

「駑馬十駕」を信念に IT系情報を中心に調べた事をコツコツ綴っています。