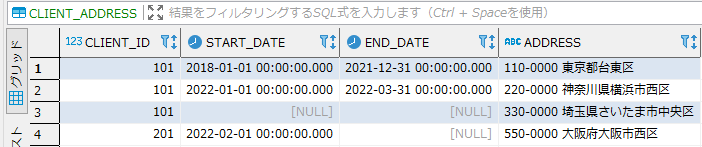
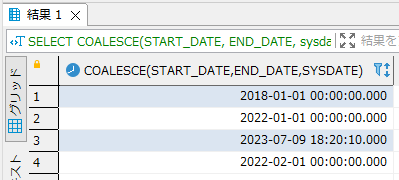
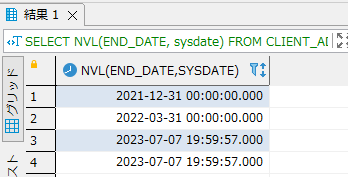
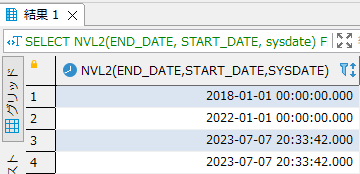
SQLの検索でよく使われる LIKE 句は便利ですが、複雑な条件指定には限界があります。
そこで強力な武器となるのが 正規表現(REGEXP)。
この記事では、基本的な使い方からよく使うパターン、さらに「SQLで利用できる正規表現の一覧」をまとめました。
1. REGEXPの基本構文
SQLでは REGEXP を用いて文字列検索を行います。
2. 使用できる正規表現の一覧(MySQL準拠)
SQLで使える代表的な正規表現を整理しました。
※DBエンジンにより若干差異あり(MySQL、PostgreSQL、Oracleなど)
| パターン | 意味 | 使用例 | ||
|---|---|---|---|---|
| ^ | 行頭にマッチ | ^A → Aで始まる | ||
| $ | 行末にマッチ | Z$ → Zで終わる | ||
| . | 任意の1文字 | c.t → cat, cot, cut | ||
| [...] | 文字クラス | [0-9] → 数字1文字 | ||
| [^...] | 否定の文字クラス | [^0-9] → 数字以外 | ||
| * | 0回以上の繰り返し | a* → \\" | a | aaa" |
| + | 1回以上の繰り返し | a+ → a, aa | ||
| ? | 0回または1回 | colou?r → color, colour | ||
| {n} | n回の繰り返し | [0-9]{4} → 4桁の数字 | ||
| {n,} | n回以上の繰り返し | [0-9]{2,} → 2桁以上の数字 | ||
| {n,m} | n〜m回の繰り返し | [A-Z]{2,5} → 2〜5文字の大文字 | ||
| | | OR条件 | cat|dog → cat または dog | ||
| () | グループ化 | (abc)+ → abc, abcabc | ||
| [:digit:] | 数字 | [[:digit:]] → 0〜9 | ||
| [:alpha:] | 英字 | [[:alpha:]] → A〜Z, a〜z | ||
| [:alnum:] | 英数字 | [[:alnum:]] → 英数字 | ||
| [:space:] | 空白文字 | [[:space:]] → 空白, 改行, タブ | ||
| [:upper:] | 大文字 | [[:upper:]] → 大文字 | ||
| [:lower:] | 小文字 | [[:lower:]] → 小文字 |
3. よく使う実践パターン
(1) 先頭・末尾の一致
(2) 日付フォーマット判定
(3) メールアドレス判定
(4) 商品コードの書式検証
(5) 拡張子フィルタ
4. REGEXPのメリットと注意点
メリット
-
複雑な条件をシンプルに表現できる
-
SQLの可読性が向上
-
データ品質チェックに有効
注意点
-
DBごとに正規表現エンジンが異なる(MySQL、PostgreSQL、Oracleで互換性に注意)
-
パフォーマンス低下の可能性があるため、大量データ処理時はインデックス設計と併用が望ましい
SQLでのREGEXPサポート比較(DBMSごと)
| DBMS | REGEXPサポート | 演算子/関数例 | 備考 |
|---|---|---|---|
| MySQL | ◎ | REGEXP, REGEXP_REPLACE | 8.0以降はICUベース |
| PostgreSQL | ◎ | ~, ~*, !~, !~* | 高度な正規表現OK |
| Oracle | ◎ | REGEXP_LIKE, REGEXP_SUBSTR | POSIX互換 |
| SQL Server | △ | (CLR関数経由) | ネイティブ未対応 |
| SQLite | △ | REGEXP(要自作関数) | デフォルト非対応 |
| BigQuery | ◎ | REGEXP_CONTAINS など | クラウドSQL |
| Snowflake | ◎ | RLIKE, REGEXP | ほぼMySQL互換 |
まとめ
REGEXPを使えばSQLの検索が格段に柔軟になります。
一覧表を参考に、ログ解析やメール判定、コード検証などに応用してみてください。
「LIKEでは表現できない…」と思ったら、REGEXPの出番です!