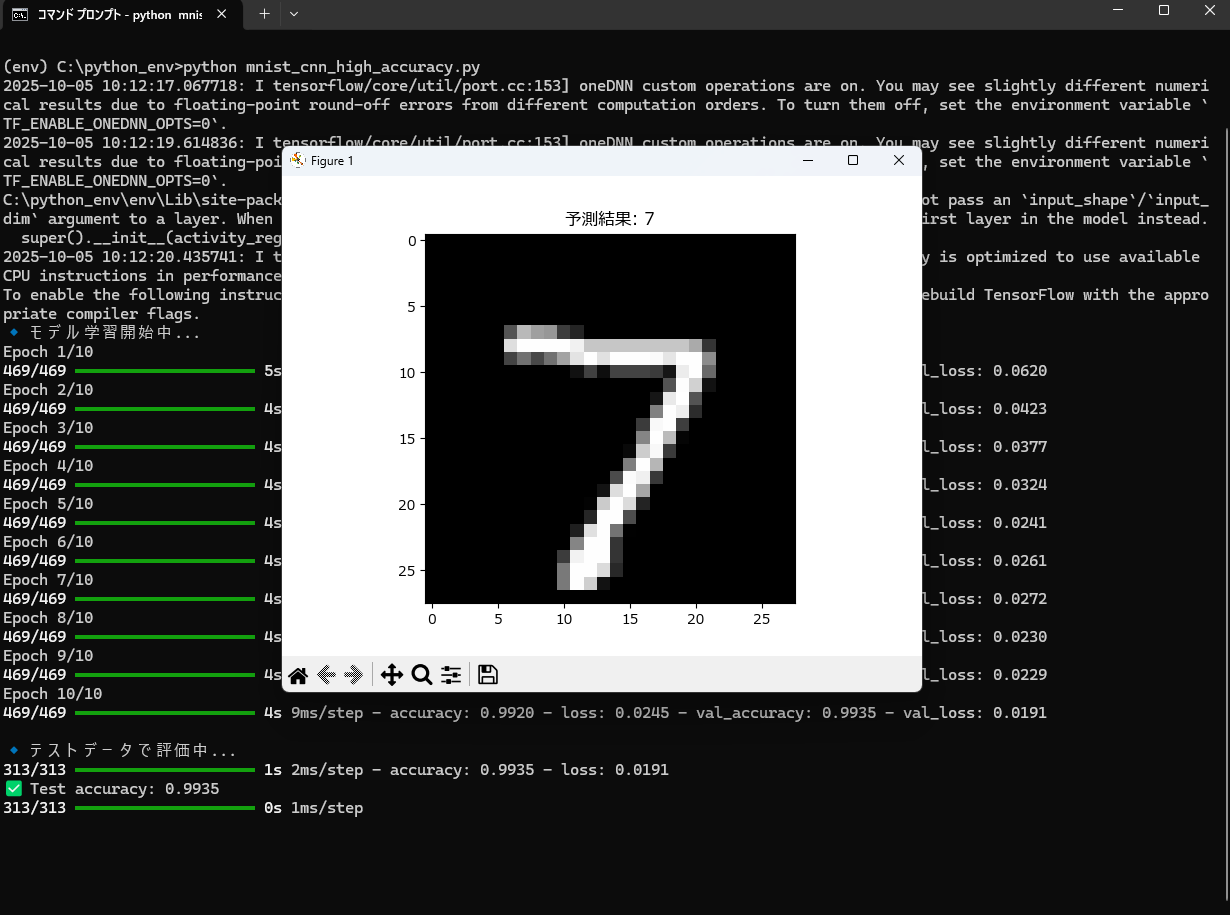
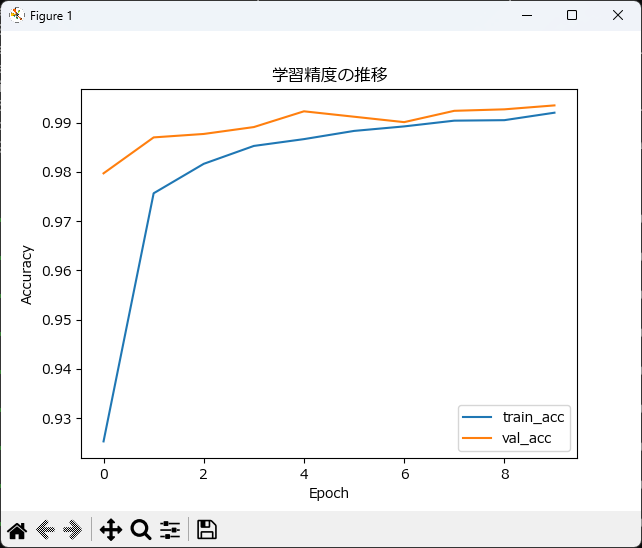
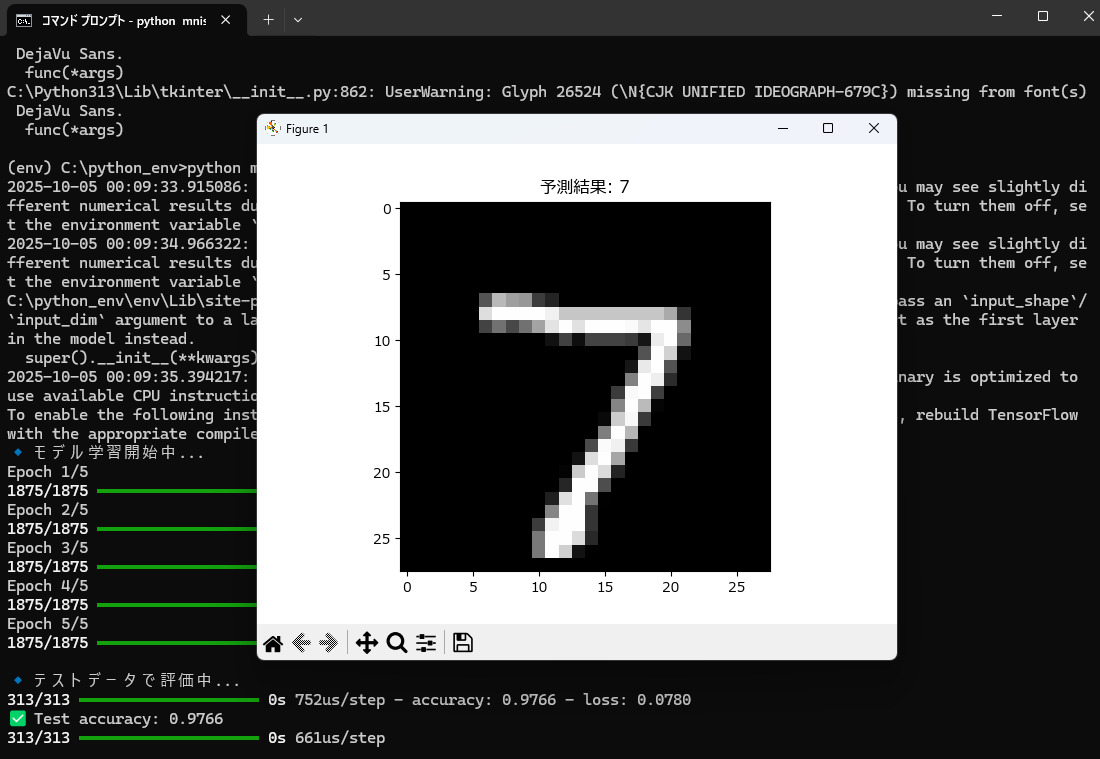
Oracleで以下のようなエラーが出ることがあります:
ORA-00054: リソースがビジー状態です。NOWAITを指定したためまたはタイムアウトが発生しました。
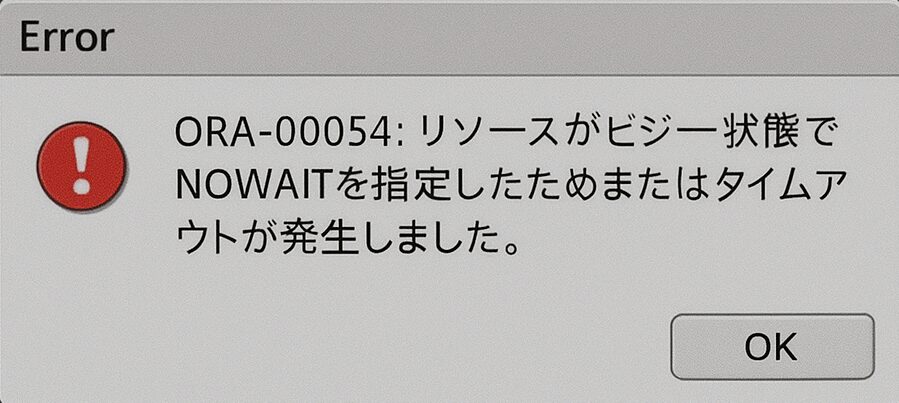
これは「対象のオブジェクトが別のセッションでロックされており、現在アクセスできない」ことを意味します。
主に DDL(CREATE、ALTER、DROPなど)を実行した際 に発生します。
🧠 主な発生原因
| 原因 | 説明 |
|---|---|
| セッションロック | 他のセッションがテーブルやインデックスを更新中でロック中 |
| 長時間トランザクション | COMMITされていないセッションが存在 |
| DDLとDMLの競合 | DML実行中にALTER TABLEなどDDLを実行しようとした |
| 自動統計・バックアップ中 | バックグラウンド処理が対象オブジェクトをロックしている |
🧩 ロック状況の確認方法
1️⃣ ロックされているオブジェクトを特定
🧰 回避策①:ロック解除(セッション切断)
他セッションが原因の場合は、該当セッションを強制終了します。
管理者権限(SYSDBA)が必要です。
🧰 回避策②:NOWAIT句またはWAIT句を利用
NOWAIT句(即時判定)
WAIT句(待機)
🧰 回避策③:時間をおいて再実行
統計収集や自動ジョブが走っている時間帯(例:夜間バッチ中)に発生しやすいため、
時間をおいて再実行 するのも有効です。
特に自動メンテナンスが有効な環境では、深夜帯に競合することが多いです。
🧰 回避策④:DDLを業務外時間に実行
DDLはオブジェクトを完全ロックするため、
業務時間内にALTERやDROPを実行すると高確率で発生します。
→ 定期メンテナンス時間帯 にスケジュール化しましょう。
⚠️ 注意点
-
KILL SESSIONは強制終了のため、他処理への影響リスク がある -
バッチ処理や自動統計のタイミングと重なると再発する
-
ロック発生元を特定し、原因セッションの対処を優先 することが重要
✅ まとめ(表)
| 対策 | 内容 | 注意点 |
|---|---|---|
| セッション確認 | v$locked_object でロック特定 | 管理者権限が必要 |
| 強制切断 | ALTER SYSTEM KILL SESSION | 他処理への影響注意 |
| WAIT句利用 | ロック解除を待つ | タイムアウト指定が重要 |
| 実行タイミング調整 | バッチや統計処理の時間帯を避ける | 定期メンテナンス枠を活用 |