前回の記事
「🧠 Pythonで学ぶ画像認識入門:TensorFlowとKerasで手書き数字を判定する方法(2) ~実践サンプルコード編~」
では、全結合層(Dense Layer)のみを使った
シンプルなニューラルネットワークで手書き数字を認識しました。
今回はその続編として、
より高い精度を実現するために
-
🌀 CNN(畳み込みニューラルネットワーク)
-
🌊 Dropoutによる過学習防止
-
⚙️ 学習率調整(Learning Rate Scheduling)
を導入した「高精度モデル版」を構築します。
🧩 動作環境(同シリーズ共通)
🧱 ステップ①:CNNを使ったモデル構築
CNNは画像認識に特化したネットワーク構造で、
人間の「目」と同じように特徴(輪郭・形・濃淡)を自動的に抽出します。
⚙️ ステップ②:学習率を調整して最適化
Adam オプティマイザの learning_rate を指定することで、
勾配更新のスピードを細かく制御できます。
📈 ステップ③:学習を実行
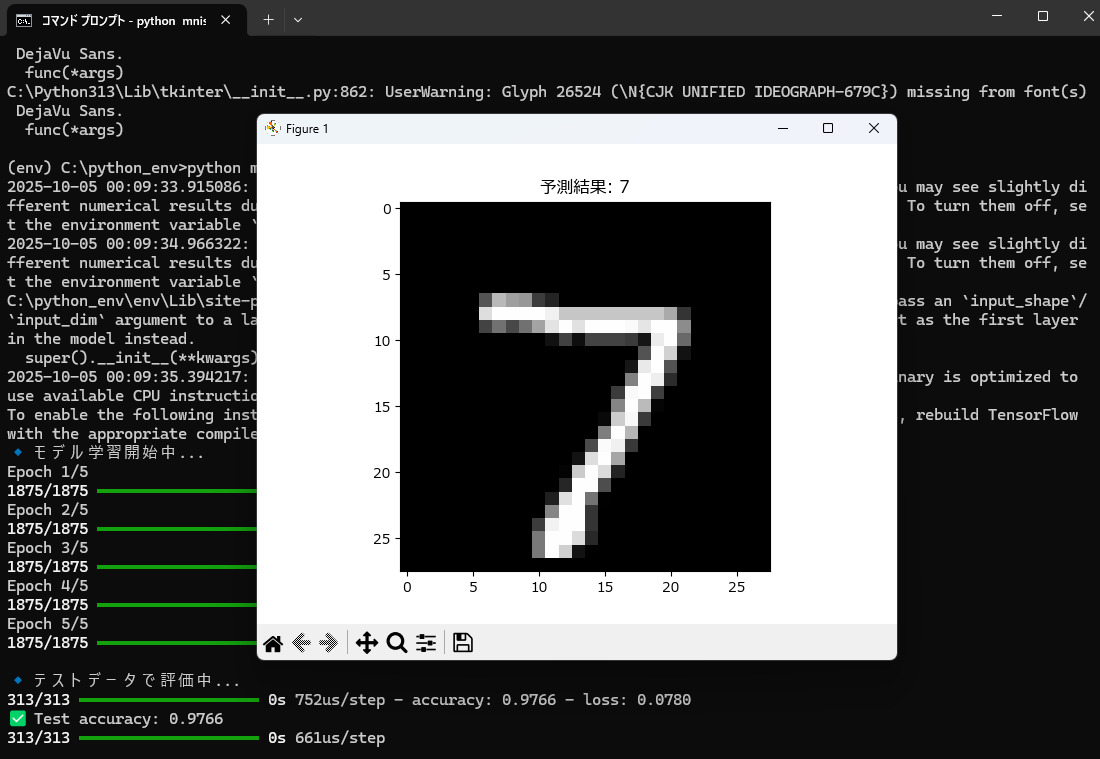
学習中の精度や損失の推移がターミナルに表示されます👇
🧾 ステップ④:テストデータで評価
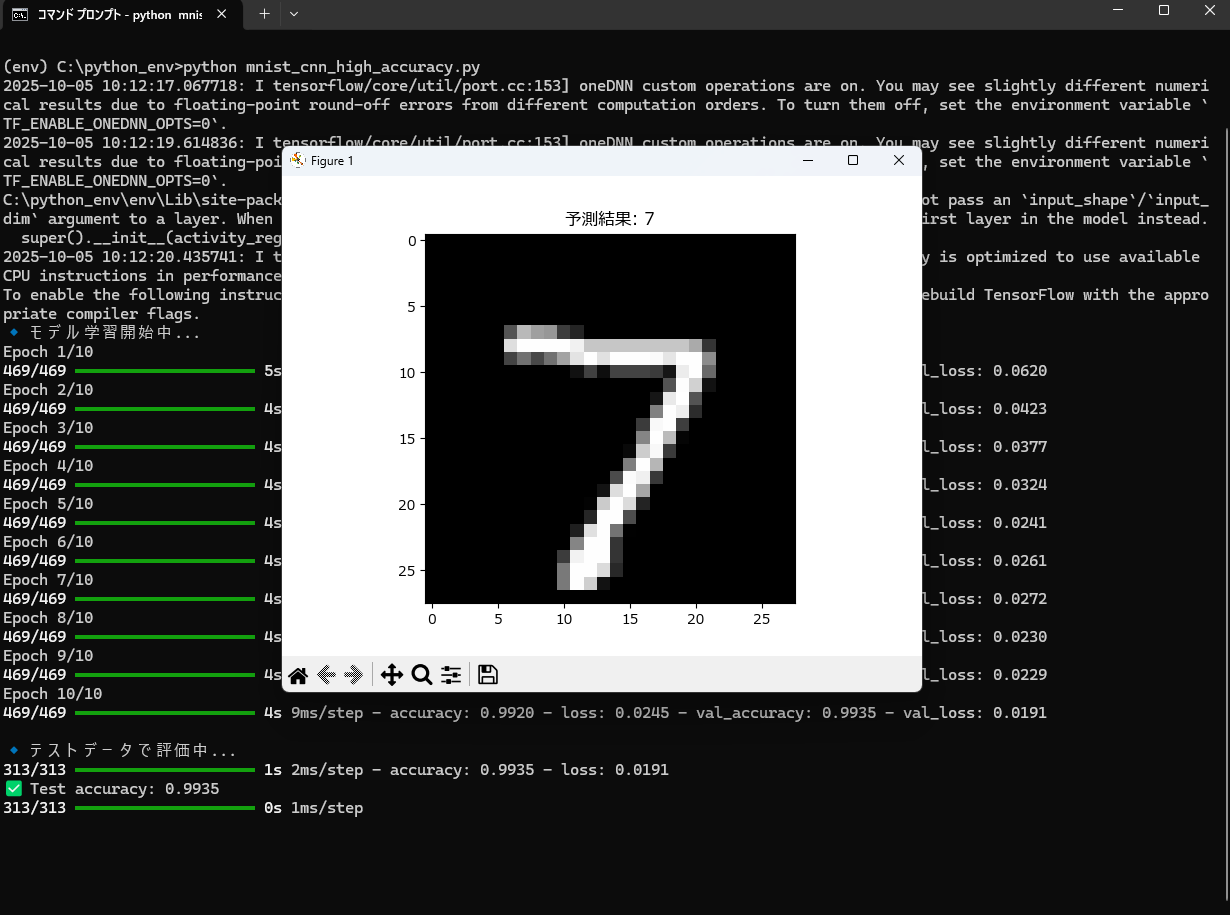
CNNを導入したことで、精度は 約99%前後 に向上します🚀
🧠 ステップ⑤:予測結果の可視化
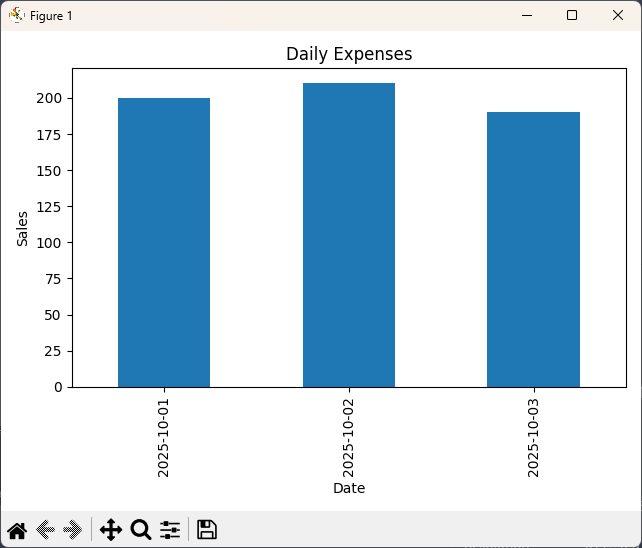
📊 ステップ⑥:精度の推移をグラフ化(オプション)
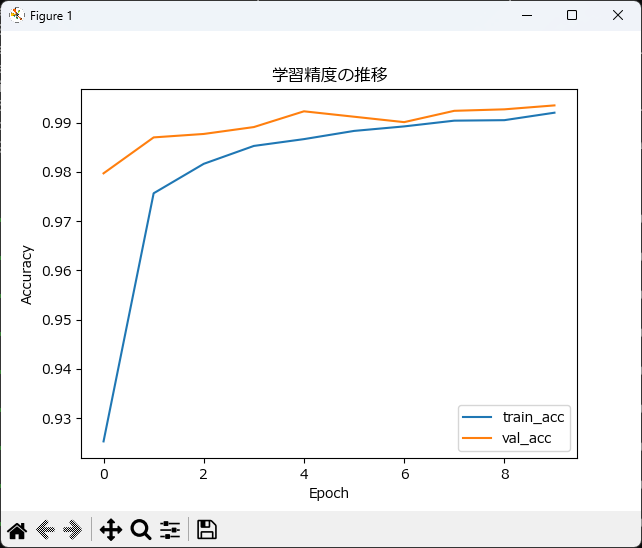
このグラフで、学習が過学習に陥っていないか確認できます。
💾 手順まとめ:ファイル保存〜実行まで
① ファイルを作成
任意のテキストエディタ(例:VSCode、メモ帳、サクラエディタなど)で
以下のコードをコピーして貼り付けてください。
ファイル名は:
② コード内容(完全版)
③ 保存場所
わかりやすくするために、
これまでと同じフォルダ内(例:C:\python_env)に保存するのがおすすめです。
④ 実行手順
1️⃣ 仮想環境を有効化(重要):
⑤ 実行結果
-
学習が進むと各 Epoch ごとの精度が表示される
-
終了時に
のような高精度結果が出る
-
その後、
-
AIが予測した数字画像(例:「7」)
-
学習精度グラフ(train_acc / val_acc)
が順に表示されます
-
⑥ 終了後
仮想環境を終了:
🚀 結果と考察
| 比較項目 | 前回(Dense) | 今回(CNN+Dropout) | 考察 |
|---|---|---|---|
| モデル構造 | 全結合層のみ | 畳み込み+プーリング | CNNが画像の空間特徴を直接学習でき、汎化性能が向上 |
| エポック数 | 5 | 10 | 学習回数は増えるが精度向上に寄与 |
| 学習時間(目安) | 約5秒 | 約20秒 | パラメータが増えるため計算時間は増加 |
| 精度(テスト) | 約97.6% | 約99.2% | CNN導入で+1〜2ポイント改善 |
| 過学習対策 | なし | Dropout(0.5) | Dropoutにより汎化が改善し、過学習を抑制 |
CNNを導入することで、特徴抽出の自動化が進み、
より安定した高精度の画像認識が可能になりました。
💡 応用ポイント
-
🔹 BatchNormalization を追加するとさらに安定化
-
🔹 データ拡張(ImageDataGenerator) で汎化性能アップ
-
🔹 モデル保存:
model.save("mnist_cnn_model.h5")
✅ まとめ
本記事では、
CNN(畳み込みニューラルネットワーク)+Dropout+学習率調整
を導入して、手書き数字認識AIを高精度化しました。
精度は 約99% に到達し、実用的な画像認識モデルの基礎が完成です。
🔜 次回予告
「(4) 学習済みモデルを使って自分の手書き画像を判定する」
自分で描いた数字画像を読み込んで、
AIがそれを正しく識別できるか試してみましょう🖋️